Amazon Aurora

Amazon Aurora:
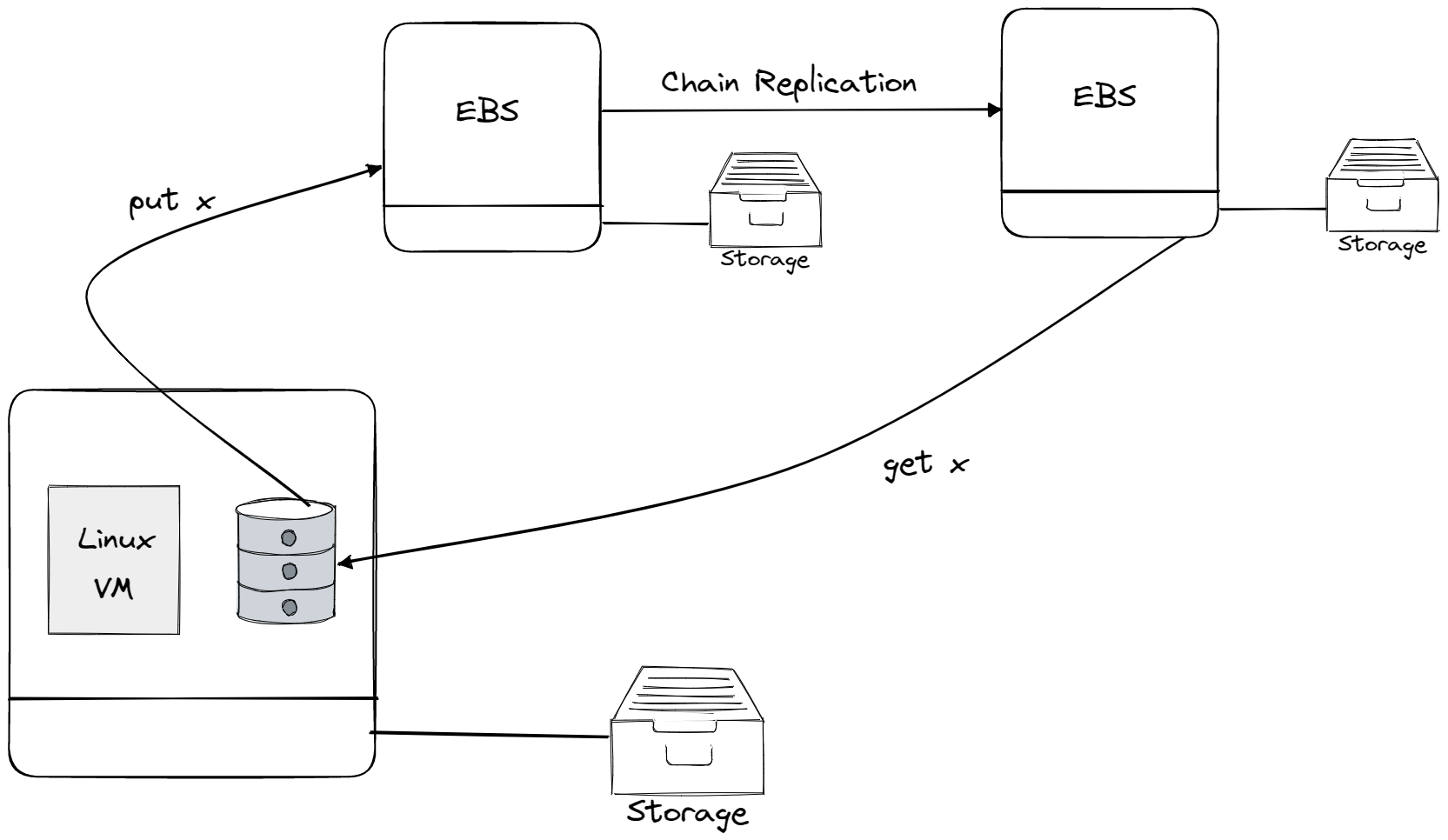
We will investigate Amazon Aurora a high-performance and reliable database service offered by Amazon. But before we do that let’s go back in time and say something about Amazon initial offerings as Ec2 and EBS. EC2 (Elastic Cloud Compute) is Amazon’s cloud computing service that allows customers to rent virtual machines. Stateless services, such as web servers, do not retain any data or state, meaning that if a virtual machine is terminated or shut down, no data is lost. Stateful services, such as databases, retain data and state and require a method to persist this data. EBS (Elastic Block Store) is a service offered by Amazon for providing storage to EC2 instances. It allows customers to create and attach virtual storage devices to their instances. Chain replication is a method of replicating data across multiple EBS volumes to provide high availability and fault tolerance. Writes are forwarded to the first replica in the chain and propagated all the way to the tail of the chain, which is then used to read the data. To maintain performance of chain replication, EBS volumes are typically placed in the same availability zone. An availability zone is a physical location within an Amazon region that is designed to be highly available and fault-tolerant. This ensures that if a failure occurs in one availability zone (imagine the whole zone going down in case of a fire or something similar), the data is still available on the replicas in the other availability zones.
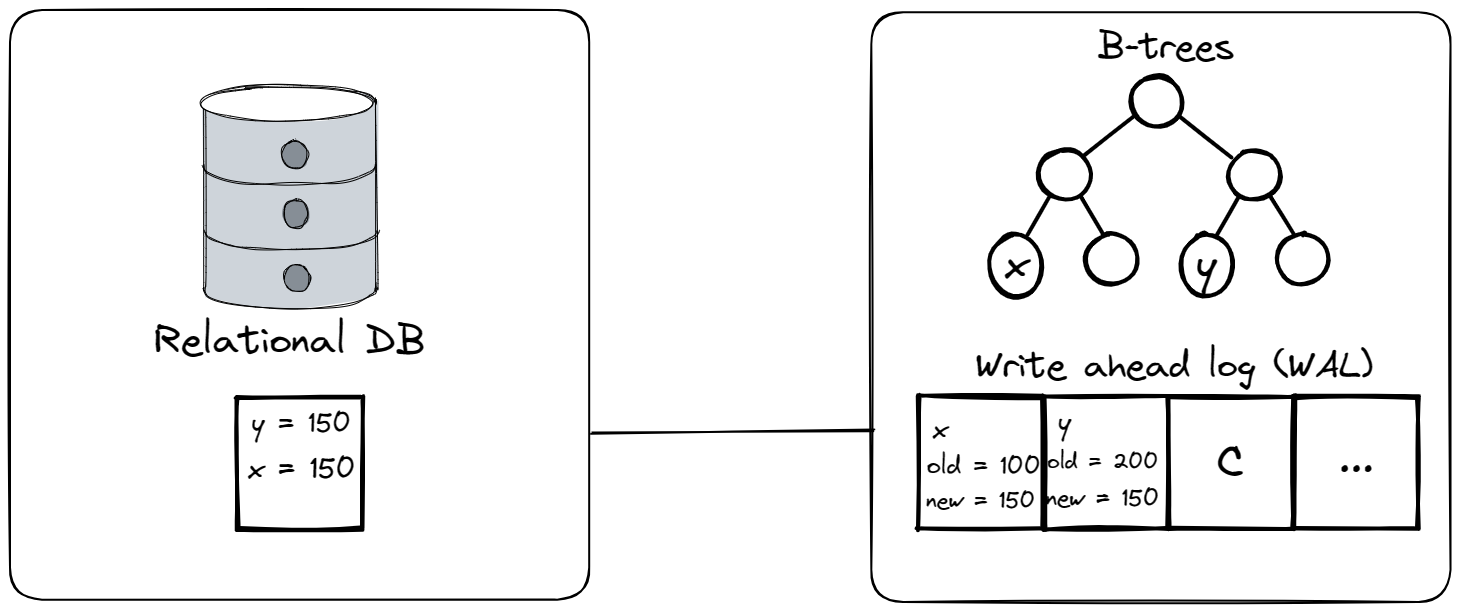
Before we move to Aurora design let’s recall what transactions are in a standard relation databases like Mysql (which Aurora uses by moving it to a more complex distributed network system). A transaction is a way of wrapping multiple operations on different pieces of data and declaring that the entire sequence of operations should appear atomic to anyone else who is reading or writing the data. Crash recovery is the process of ensuring that after a crash, either the entire transaction’s worth of modifications are visible or none of them are. So does a releational database like Mysql provide this support? Using B-trees and WAL (write ahead logs). Any transaction is first written to the log and only written to the disk (b-tree) once we get a commit log message. WAL works by storing both the old and new values of data before a change is made, in case a crash occurs and the data needs to be restored to its previous state. This undo function allows for quick crash recovery without losing any data. To learn mode about WAL and B-trees let’s get to our fundamentals series
B-trees
. On the image below you can see what happens when we have a transaction which is updating some records x and y, let’s say with initial values x=100 and y=200, the transactions takes 50 from y and gives it to x. Note that x and y can be arbitrarily complex records in a database (whole rows for example), but for our example it’s enough to show it as if x and y were plain integer variables.
RDS (Relational Database Service) was a first attempt to replicate a database across multiple availability zones to ensure that if a data center goes down, the database contents can be retrieved without missing any writes. RDS stores its data pages and log in EBS (Elastic Block Store) and for every write that the database software does, Amazon also sends those writes to a special set up in a second availability zone on a separate computer. This setup of RDS provides better fault tolerance as it maintains a complete, up-to-date copy of the database in a separate availability zone. However, this setup is not as fast as it involves sending large volumes of data across two separate data centers. RDS is costly as it involves replicating 8kb pages across multiple availability zones, which requires a lot of network capacity. Aurora, on the other hand, uses Amazon’s own software and replicates data across 6 replicas in 3 availability zones. Instead of replicating entire pages, Aurora replicates logs, which is key to its success. Aurora also uses specialized storage that is not general-purpose, but rather optimized for reading MySQL Write-Ahead Logs. The fault tolerance goals of Aurora are to ensure that even with one availability zone down, writes can still be made and with one availability zone and one server down, data can still be read. By utilizing log based replication and quorum based writes Aurora offers a fast re-replication process when one of the replicas (all one whole zone) goes down. Quorum-based writes are used in Aurora, where N=6 replicas, W=4 and R=3. Version numbers are used with writes to ensure consistency. To learn more about quorum check out our fundamentals series Leaderless Replication .
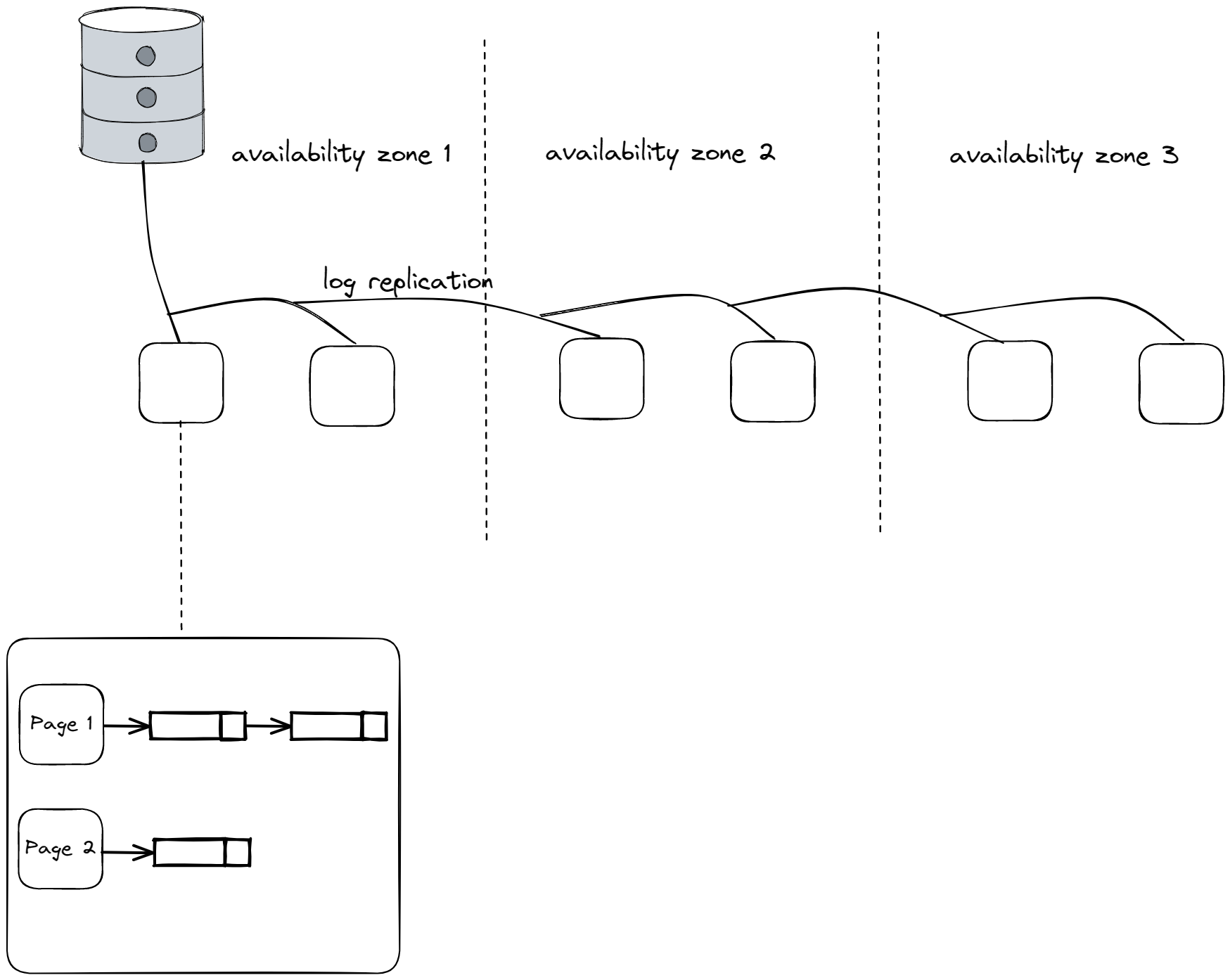
Storage servers store log records of changes made to data pages. These log records are applied to the relevant data pages when a read request is made for them by the database server. The database server writes log records but reads data pages (lazy approach) and keeps track of the highest contiguous log entry number for each storage server, so it knows which storage servers are up-to-date and can send read requests for a page to just one of them. This eliminates the need for quorum reads, except during re-replication of the database server which is triggered by some monitoring that creates a new EC2 instance. In case of failures, the system undoes partially done transactions and maintains the consistency of logs on different storage servers.
What about large databases? Aurora deals with large databases by splitting them up into smaller segments called protection groups, each containing 6 replicas. Each protection group stores a subset of the data pages and all the log records that apply to those data pages. This allows the database to be larger than the storage capacity of a single machine. Additionally, in the event of a storage server crash, Aurora aims to quickly re-replicate the data to maintain consistency and avoid data loss. This is done by identifying which protection groups store the data affected by the log records and sending the log record to those specific protection groups. This ensures that each protection group has all the relevant log records for the data it stores. Additionally, the database has a master writer and multiple read-only replicated servers, further improving the performance for read only operations and rebalancing the load from one master database server.