Facebook Memcached

Facebook Memcached:
Let’s take a look on the natural evolution of a system and we will introduce the Memcached which is a well known, simple, in memory caching solution developed by Facebook.
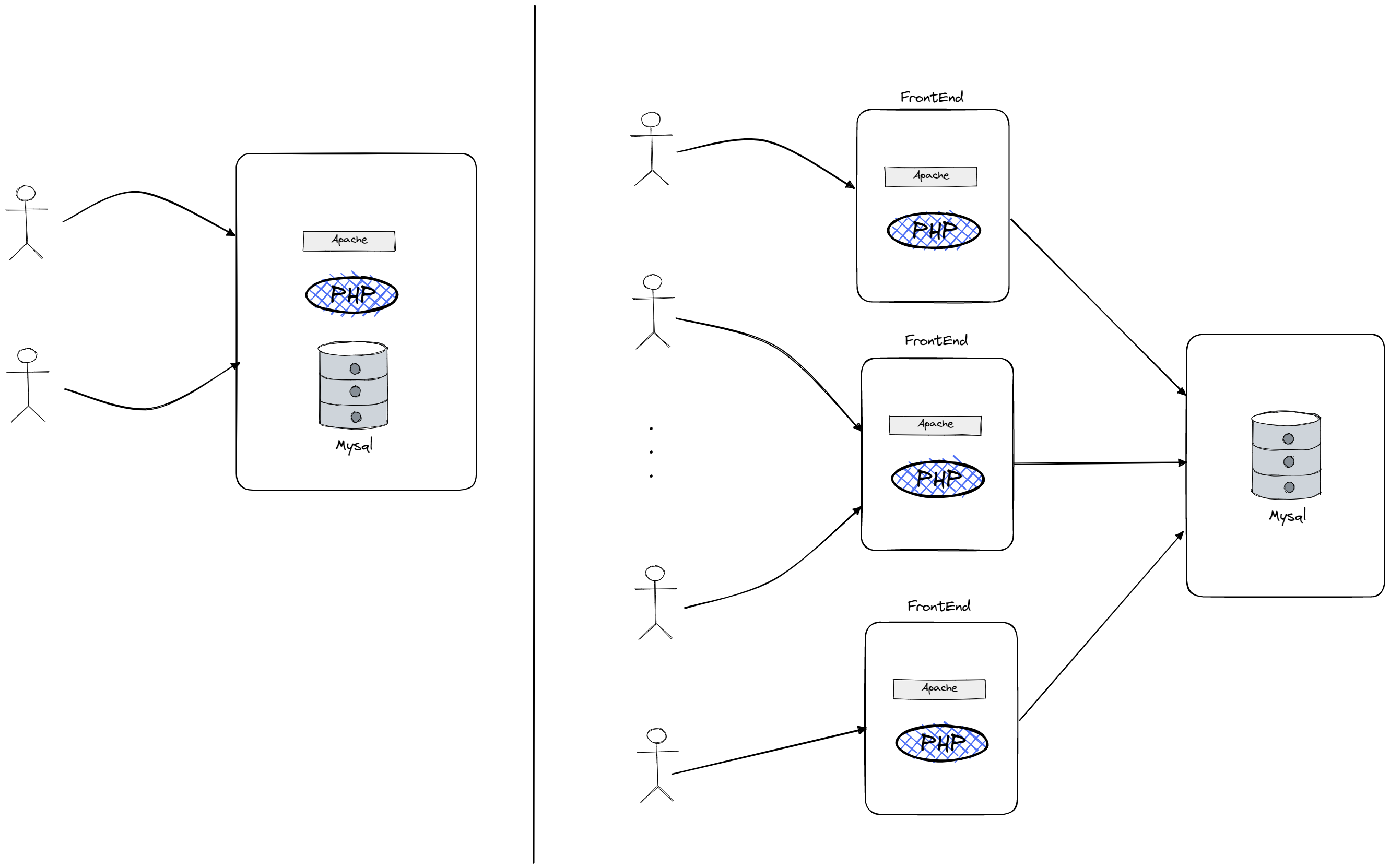
When building a website, the initial focus is often on building features rather than high-performance infrastructure. As the website grows and receives more traffic, the PHP scripts (taking PHP as example since it’s Facebook) may take up too much CPU time, leading to the need for more horsepower for the scripts. This can be achieved by adding front-end servers that run the web server and PHP scripts, and a database server that stores the data. As the website continues to grow and receive more traffic, the database server may become a bottleneck, leading to the need for a distributed data storage system.
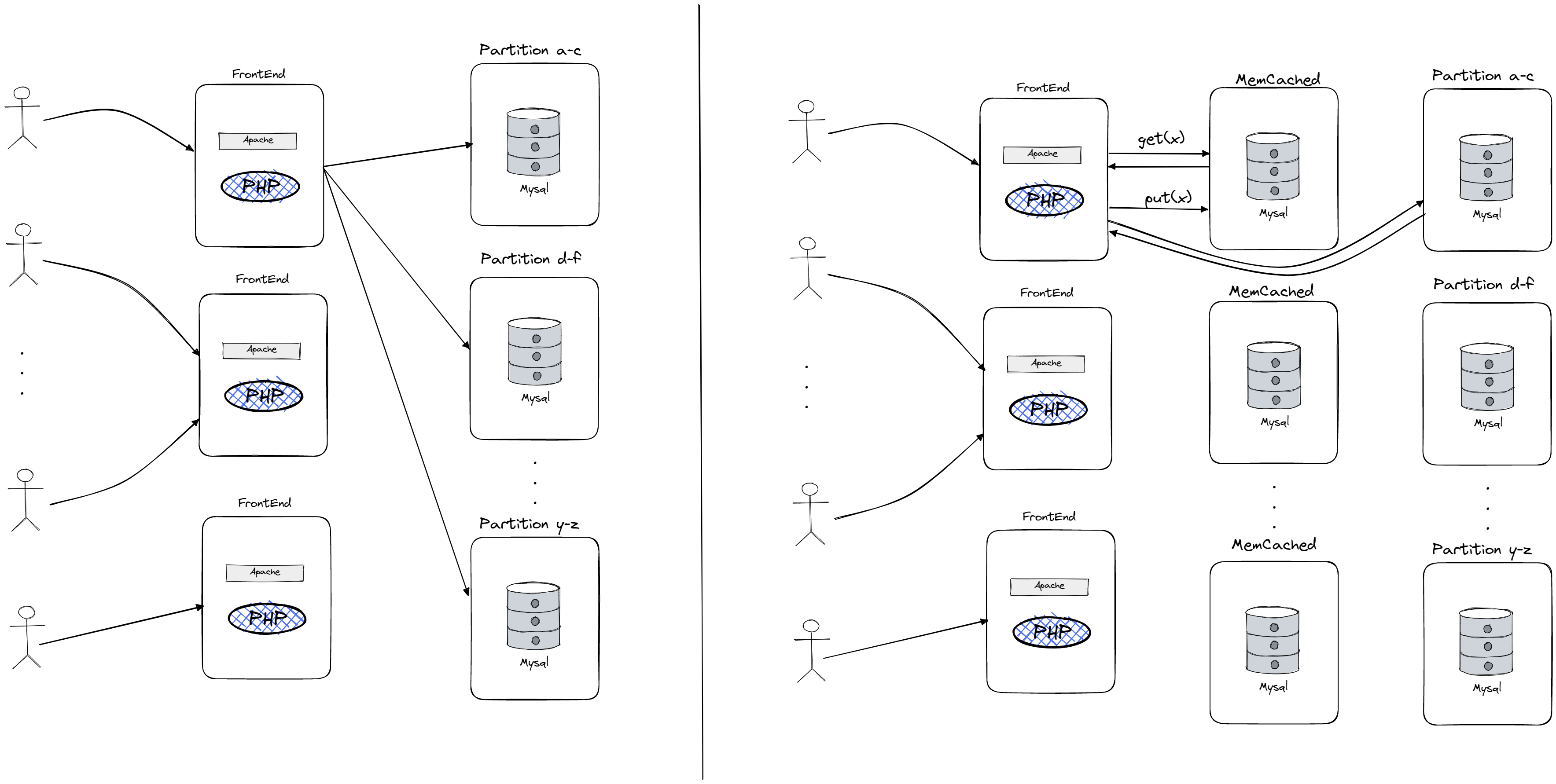
As websites grow and receive more traffic, it may become necessary to add multiple database servers to improve performance. This can be done through sharding/partitioning, in which the data is divided and stored across multiple servers. While this can improve performance by allowing for parallel reading and writing of data, it can also be difficult to implement and may require modifying the software running on the front-end servers. Additionally, using database servers can be expensive and may not be able to handle a large number of reads. As a result, it may be more cost-effective to add a caching layer using a system like Memcached, which can improve performance by allowing for more reads per second and reducing the load on the database servers. Memcached allows for easier scaling and the ability to add new cache servers without modifying the software on the front-end servers. Facebook uses a combination of these architectures, with Memcached serving as a caching layer between the front-end servers and the database servers. It’s also important to note that primary goal of caching here is not to reduce latency, but to “hide” the load from DB which it couldn’t handle if left without caching layer.
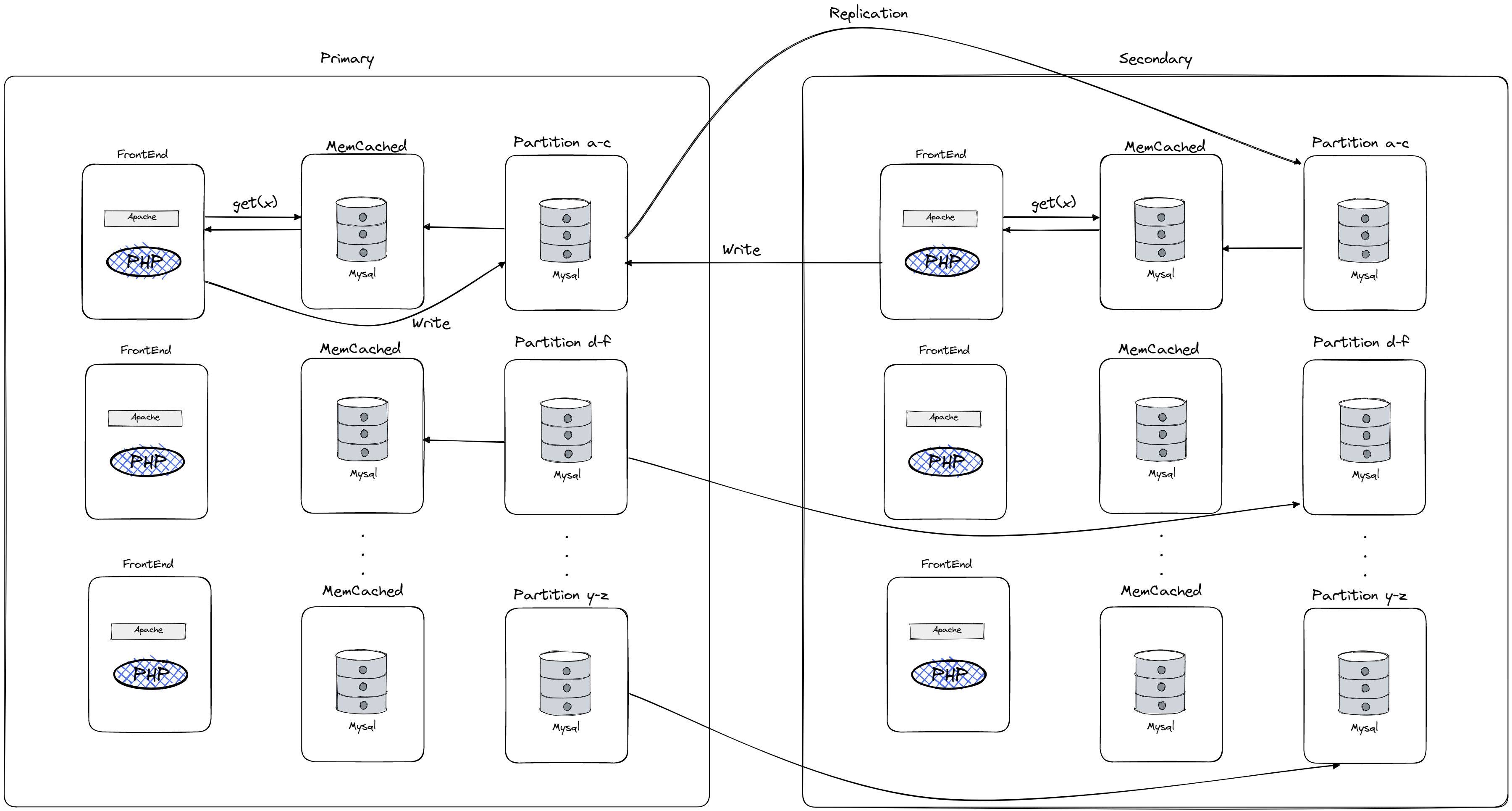
As you can see we have multiple data centers, also known as regions, which are located on opposite coasts of the United States. Each data center has a set of database servers running mySQL, memcached servers, and front-end servers. The data in each data center is a complete replica of the other data center, with updates to the data being sent asynchronously through log replication (also any replicated change from primary to secondary will be propagated as cache invalidation to secondary respective memcached server from the database shard). This allows for a lag of a few seconds between the data in the primary and secondary data centers. The front-end servers in each data center typically read from memcached and, if the data is not found there, from the local database. The overall goal of this setup is to improve performance by allowing users to access data from a nearby data center and to provide consistency for data updates made by users.
Memcached uses look-aside caching as described in the get and put procedures below:
Read
value = get(key)
if value is null
value = fetch from DB
set(key, value) in cache
Write
send (key,value) to DB
delete(key) in cache
So on read we’re first reading first from cache and if we have a miss we fetch the data from DB and update the record in the cache. On write we first send a write request to DB, and then delete the key from the cache. Why do we do delete from cache? The reason is twofold, first we want for FE to read it’s own writes, in other words if we insert something in DB, if we try to fetch it immediately after it we will have a cache miss and we will have to go to database to fetch the new data and update the cache. Second reason is that you can think of delete as idempotent, in other words if we had multiple race updates on cache (imagine incrementing value for a certain key) that would lead to inconsistence, delete operation will always produce the same result no matter how many time we execute it.
Facebook used a combination of partitioning data over memcache servers and replicating data on multiple servers. They partitioned data by hashing keys to determine which memcache server should store each piece of data. This allowed them to serve data from a single server, which was efficient for communication. However, it also meant that hot keys (frequently accessed data) could still overload a single server. To address this, they also used replication, with each front-end server communicating with a single memcache server. This allowed them to serve requests for the same key in parallel, improving performance for hot keys. However, it also meant that they had to store multiple copies of each piece of data, limiting the total amount of data they could cache.
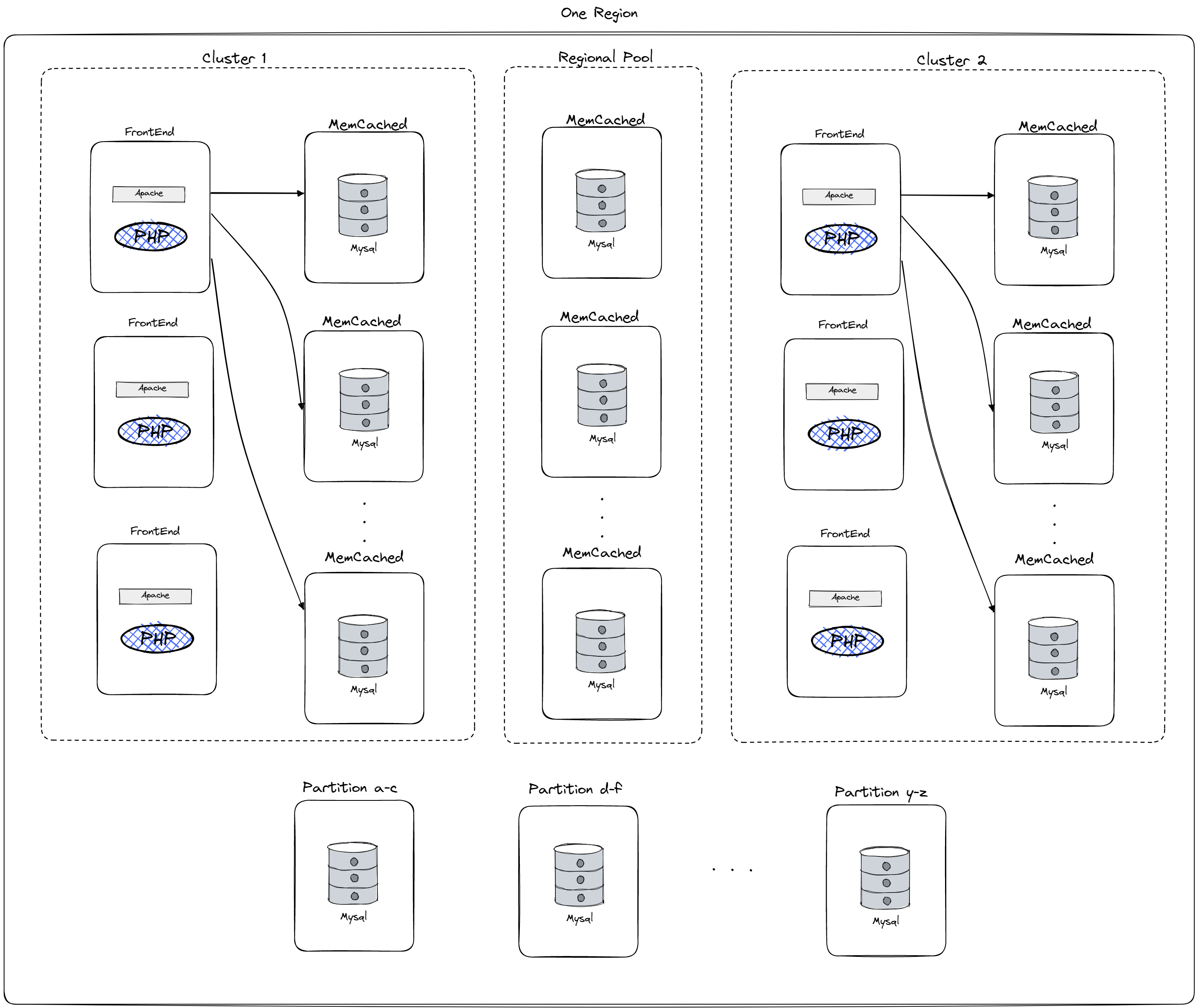
Inside one region we have groups of FE and Memcached server grouped into clusters. Each front-end in a cluster talks only to the memcache servers in that same cluster, and the memcache servers in a cluster store replicas of popular data. Using both partitioning and replication allows Facebook to achieve parallel serving of popular data and improve performance. Additionally, using multiple clusters allows them to limit the growth of n-squared communication patterns, serve popular keys in parallel and reduce the size and cost of the underlying network. Additionally in each region we have regional pool which stores not popular keys additionally lifting the load from the clusters. When adding a new cluster the system would suffer from a lot of initial cache missing and it would overload the DB, to cope with this cold start approach is implemented where a new “cold” cluster would read from the already up-and-running hot cluster to populate it’s cache.
Additionally to prevent the “thundering herd” problem, where multiple front-end servers request the same data from the database simultaneously after a cache miss, they use a leasing system where only one front-end is allowed to request the data from the database at a time. To avoid “in-caste congestion,” they limit the size of each cluster to prevent a single front-end from requesting data from too many memcache servers at once. Leases are also used to cope with “race” problem where we have two FE updating the same key, if the first FE has a cache miss and get the data from db, but in between second FE writes a new value for the same key in db and invalidates the cache by deleting that key just for the FE to store the stale data retrieved previously in the cache we would have a permanent cache inconsistence since we would read stale data from the cache and never do a trip again to database to check for new data. So in pair with read or miss for the key we also get a lease from the memcached server and on delete both key and lease for that key is deleted, then on writing to cache first FE will have invalid lease since it was deleted by request from second FE.