Google Spanner Design

Google Spanner Design:
Spanner is a distributed database system that allows for transactions to be run over widely separated data, meaning data that may be scattered across the internet and different data centers. This is a challenging problem, as transactions typically require all of the data involved to be stored in a single location in order to ensure consistency and avoid conflicts. However, it is often desirable to have data spread out across the network for reasons such as fault tolerance and ensuring that data is available to those who need it.
To achieve this, Spanner uses a combination of two-phase commit and Paxos replication to ensure the consistency of its data, even when it is distributed across multiple locations. It also utilizes synchronized time to enable efficient read-only transactions. These innovations have made it possible for Spanner to support strong consistency, including serializable transactions and external consistency, which ensures that any modifications made by one transaction are visible to subsequent transactions.
Spanner was initially developed to support Google’s advertising system, which required transactions that could span multiple shards of data and strong consistency. The system has proven to be successful and is now used by many different services within Google, as well as being offered as a product for Google’s cloud customers. It has also inspired other research and systems, such as CockroachDB, which incorporates many of the design elements of Spanner.
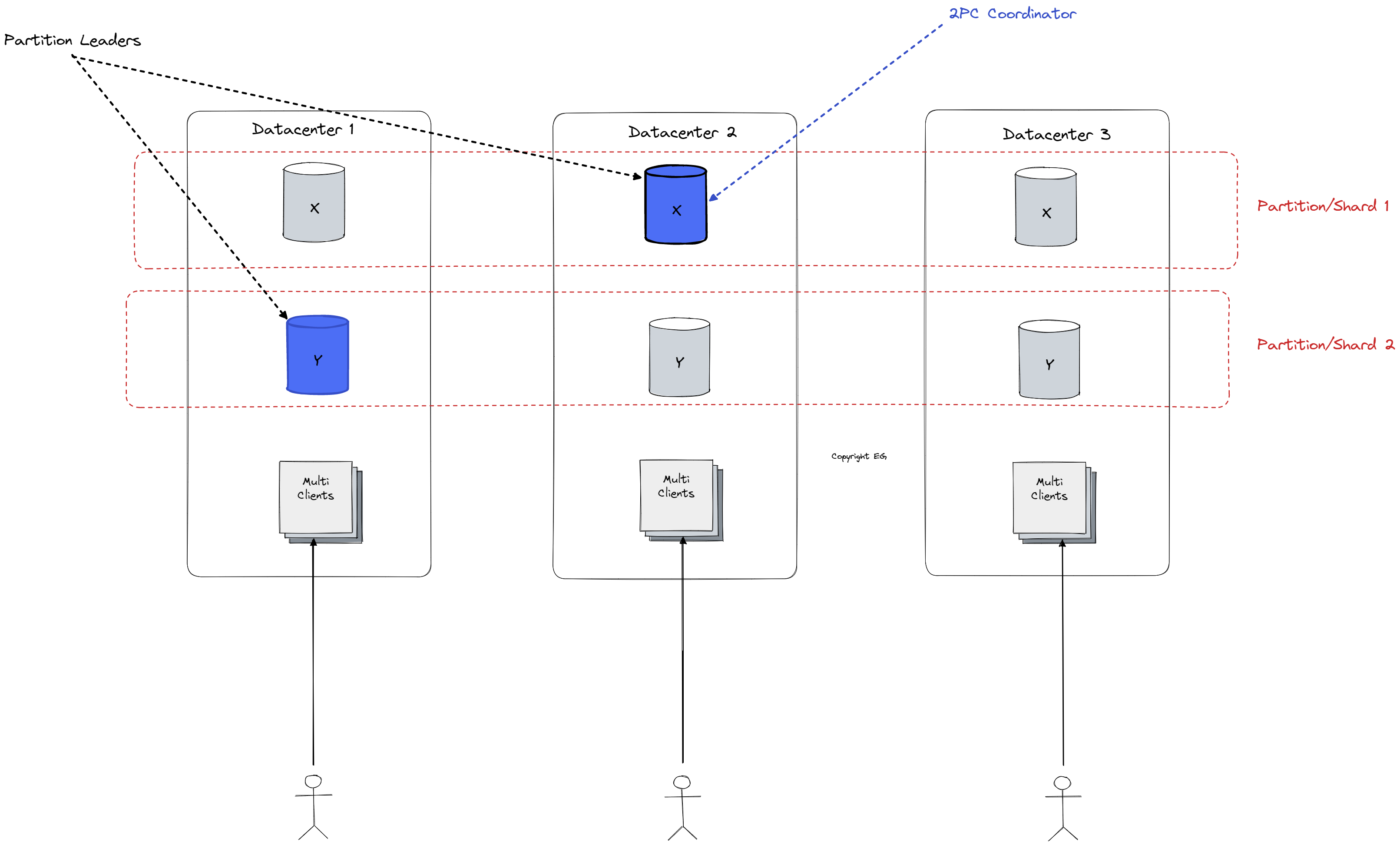
As we see on high level design overview above the data is sharded/partitioned across multiple database instances to cope with load increase while also having replication across multiple datacenter (availability zones) to provide high availability and fault tolerance while also decreasing latency because of replicas locality/proximity to the user. To achieve serializable distributed transactions (as we might need multiple separated datacenters for one transaction) it combines Two-Phase Locking for serializability and Two-Phase Commit (2PC) for cross-shard atomicity. Since for Two-Phase Commit (2PC) the coordinator might be single point of failure Spanner declares one of paxos groups as coordinators (in the diagram we have second replica chosen as leader for the first Paxos replicate group but it is also coordinator for distributed transactions). The replicated state machine in Spanner uses Paxos to establish an order for client commands, with consensus being used to determine which command goes in which slot. This ensures that the commands are processed in the correct order and helps to maintain the consistency of the data. Paxos enables leader election protocol similar to those of Raft. As you see most of the underlying approaches can be boiled down to fundamentals which we discussed in our System Design Fundamentals .
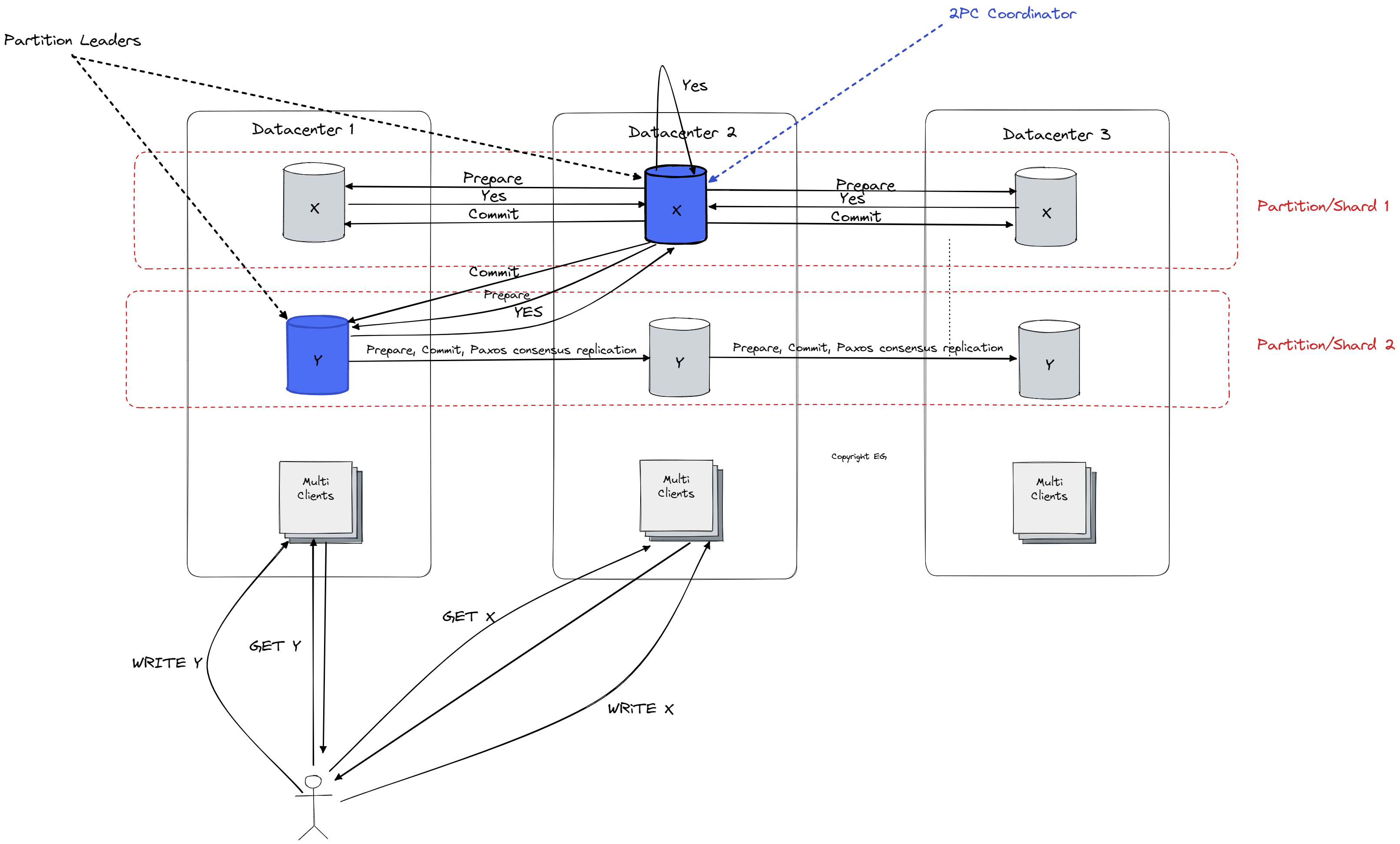
A (distributed since it the case above we read from two data centers) transaction in Spanner typically involves a client machine initiating a transaction and specifying which records it wants to read and write. To avoid conflicts and ensure the consistency of the data, the client must first perform all of its reads and then at the end of the transaction perform all of its writes simultaneously as part of the commit process. To read a record, the client sends a request to the leader of the shard that holds the record, which returns the current value of the record and sets a lock on it. If the lock is already set, the leader will not respond to the client until the current transaction releases the lock by committing (Two-Phase Locking). The client then repeats this process for any additional records it needs to read. Once it has completed all of its reads, the client performs its writes by choosing one of the Paxos groups to act as the transaction coordinator and sending updated values for the records to the leaders of the relevant shards. The leaders then check for any conflicts with existing locks and, if none are found, apply the updates and release the locks. Paxos is doing a similar thing when it comes to state replication between replicas, the leader sends a prepare message to the follower and waits for the majority (consensus) to answer with yes to commit the transaction. Note that in 2PC we have a guarantee that all participants will have to answer yes for us to continue but with paxos this is not the case, so we don’t really have guarantee we will have Linearizable reads (for this we will have to utilize Spanner synchronized time). If a conflict is detected, the transaction is rolled back and the client is notified. Once all of the updates have been applied and the locks released, the transaction is considered committed and the process is complete (Two-Phase Commit (2PC)).
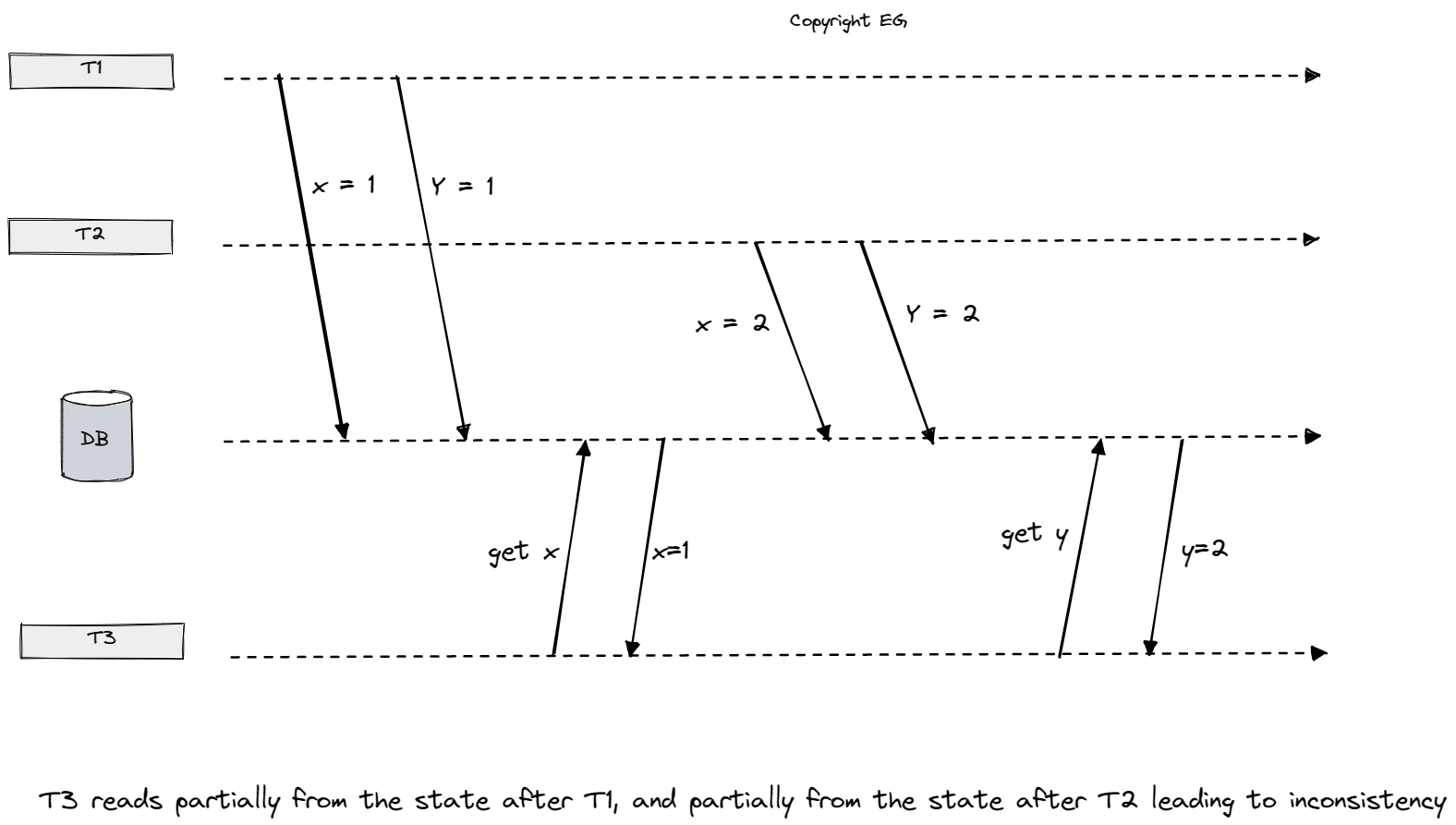
To improve efficiency, Spanner also has a design for read-only transactions that eliminates the need for locks and 2PC, allowing for faster reads and less complexity. The main constraints on these read-only transactions are that they must still be serializable, meaning that they must fit neatly between read-write transactions, and they must have external consistency, meaning that they should not see stale data and must see any committed writes from prior transactions. As in the example we can’t just read the latest value since we could be reading one part before another transaction has executed and one part after that same transaction is committed, which leads to inconsistency. Let’s say for example we have two bank accounts and if we make a transfer between them following the example above we could come to a situation where we read the balance from our first account before the transaction and the balance of our second account after transaction has committed making an impression that we didn’t lose any money from first account and gained some on the second which of course is not acceptable.
Also another issue is that read-only transactions need to read a large number of objects in a database, such as a backup or audit process, can be disruptive when using two-phase locking. This is because they would need to place a read lock on the entire database, preventing other clients from writing to the database for the duration of the process. It is therefore important that large read-only transactions can be executed in the background without requiring locks, so that they do not interfere with concurrent read-write transactions. So how does Spanner do consistent read only transaction without locks?
Spanner allows read-only transactions to read from a consistent snapshot of the database, meaning that the transaction observes the database as it was at a single point in time, even if some parts of the database are updated by other transactions while the read-only transaction is running. This is achieved through the use of multi-version concurrency control (MVCC), a form of optimistic concurrency control that assigns a commit timestamp to every transaction and tags every data object with the timestamp of the transaction that wrote it. When an object is updated, old versions (each tagged with a timestamp) are stored in addition to the latest version. A read-only transaction’s snapshot is defined by a timestamp, and it reads the most recent version of each object that precedes the snapshot timestamp, ignoring any object versions whose timestamp is greater than the snapshot timestamp. Spanner’s implementation of MVCC is notable for the way it assigns timestamps to transactions. It’s also important to note that snapshot by itself it’s not enough to have a linearizable read transactions (since we could still read stale data), but combined with the spanner’s timestamp system we can achieve consistent reads.
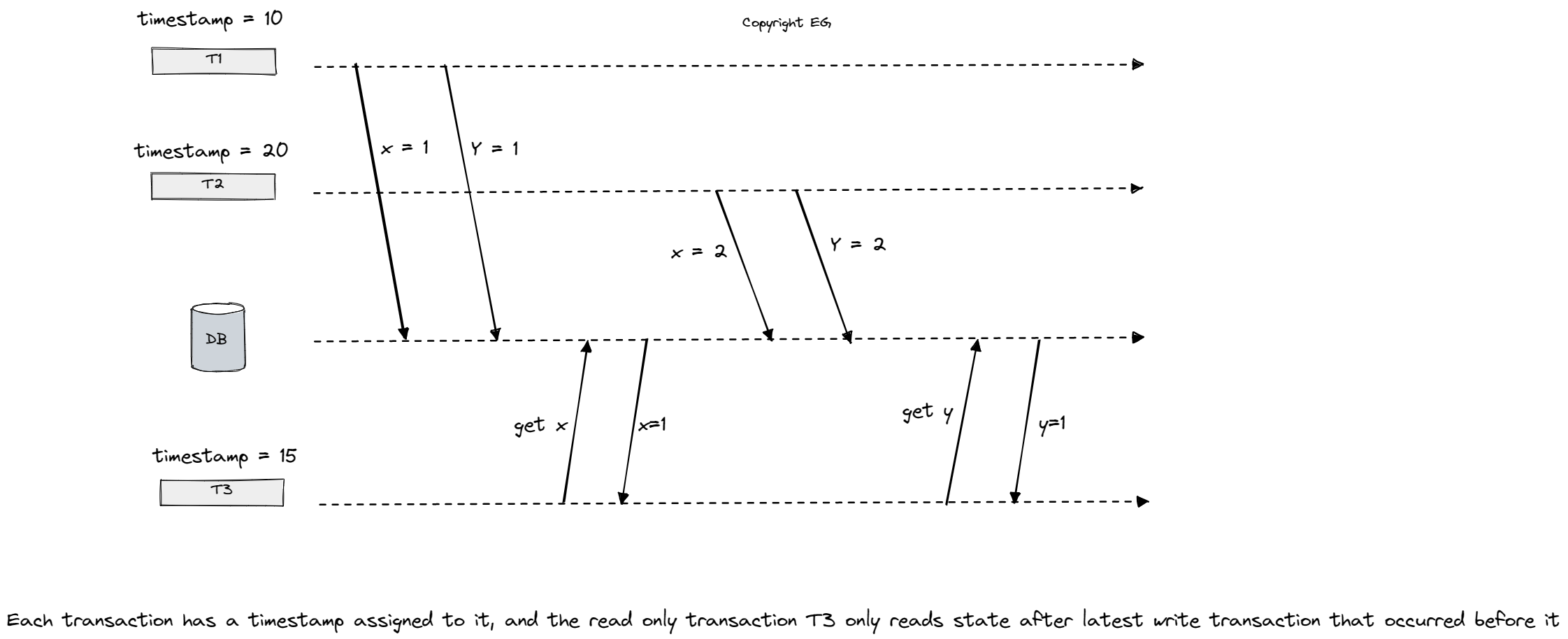
How does Spanner assign timestamps? Spanner’s TrueTime mechanism helps to address the issue of unsynchronized clocks in practical systems. TrueTime is a system of physical clocks that returns an uncertainty interval rather than a single timestamp. The errors introduced by these clocks can be accounted for by considering factors such as the manufacturer’s reported error bounds for atomic clocks, the quality of signals from satellites in range for GPS receivers, the round-trip time for synchronizing clocks over a network, and the drift rate and time since last sync with a more accurate clock for quartz clocks.
In Spanner, when a transaction Ti wants to commit, it obtains a timestamp interval [ti_earliest, ti_latest] from TrueTime and assigns ti_latest as the commit timestamp for Ti. However, before the transaction can actually commit and release its locks, it must first pause for a duration equal to the clock uncertainty period δi = ti_latest − ti_earliest. So if T2 begins later in real time than T1, the earliest possible timestamp that could be assigned to T2 must be greater than T1’s timestamp. This also ensures that the timestamp of the transaction is less than the true physical time at the moment when the transaction commits, and that the timestamp intervals of different transactions do not overlap, even if the transactions are executed on different nodes with no communication between them. To keep the uncertainty interval as small as possible, Google installs atomic clocks and GPS receivers in each datacenter and synchronizes the quartz clocks on every node with a local time server every 30 seconds. The resulting low network latency helps to minimize the clock error introduced by network latency. If network latency increases, TrueTime’s uncertainty interval grows accordingly to account for the increased error.
To summarize, TrueTime provides upper and lower bounds on the current physical time by taking into account uncertainty, uses high-precision clocks to keep the uncertainty interval small, and waits out the uncertainty interval to ensure that timestamps are consistent with causality. By using these timestamps for multi-version concurrency control, Spanner is able to provide serializable transactions without requiring any locks for read-only transactions, keeping transactions fast and not requiring clients to propagate logical timestamps.