Partitioning

Partitioning
Sharding is a technique used to improve the scalability and performance of databases by dividing the data into smaller partitions, or shards. Each shard is a separate database that can be stored on its own node or processor. This allows the workload to be distributed across multiple nodes, improving the overall throughput and capacity of the system. Replication can also be used to store copies of each shard on multiple nodes for fault tolerance.
There are several ways to partition data, including randomly, by key range, or by hash of the key. Random partitioning is the simplest approach, but it requires querying all nodes in parallel to find a specific record. Key range partitioning assigns continuous ranges of keys to different shards, making it easy to perform scans. However, this method can lead to hot spots if certain access patterns result in uneven distribution of data. Hash partitioning uses a good hash function to uniformly distribute the data across shards, avoiding hot spots. However, it is important to carefully choose the boundaries of the hash ranges to ensure an even distribution of data. Range queries, which allow you to retrieve records within a specific range of values, can become inefficient when data is partitioned because keys that were once adjacent may now be scattered across different shards. As a result, any range query must be sent to all partitions, which can impact performance.
Hot spots, or partitions with disproportionately high load, can also be a problem in sharded systems. While it is not always possible to avoid hot spots entirely, application design can help to reduce the skew and distribute the workload more evenly. For example, adding a random number to the beginning or end of the key can help to spread writes across different keys, while reads may require extra work to combine the results.
Partitioning and Secondary Indexes
Secondary indexes, which allow you to search for records based on a non-unique attribute, can become more complex when data is partitioned. There are two main approaches to partitioning secondary indexes: by document and by term.
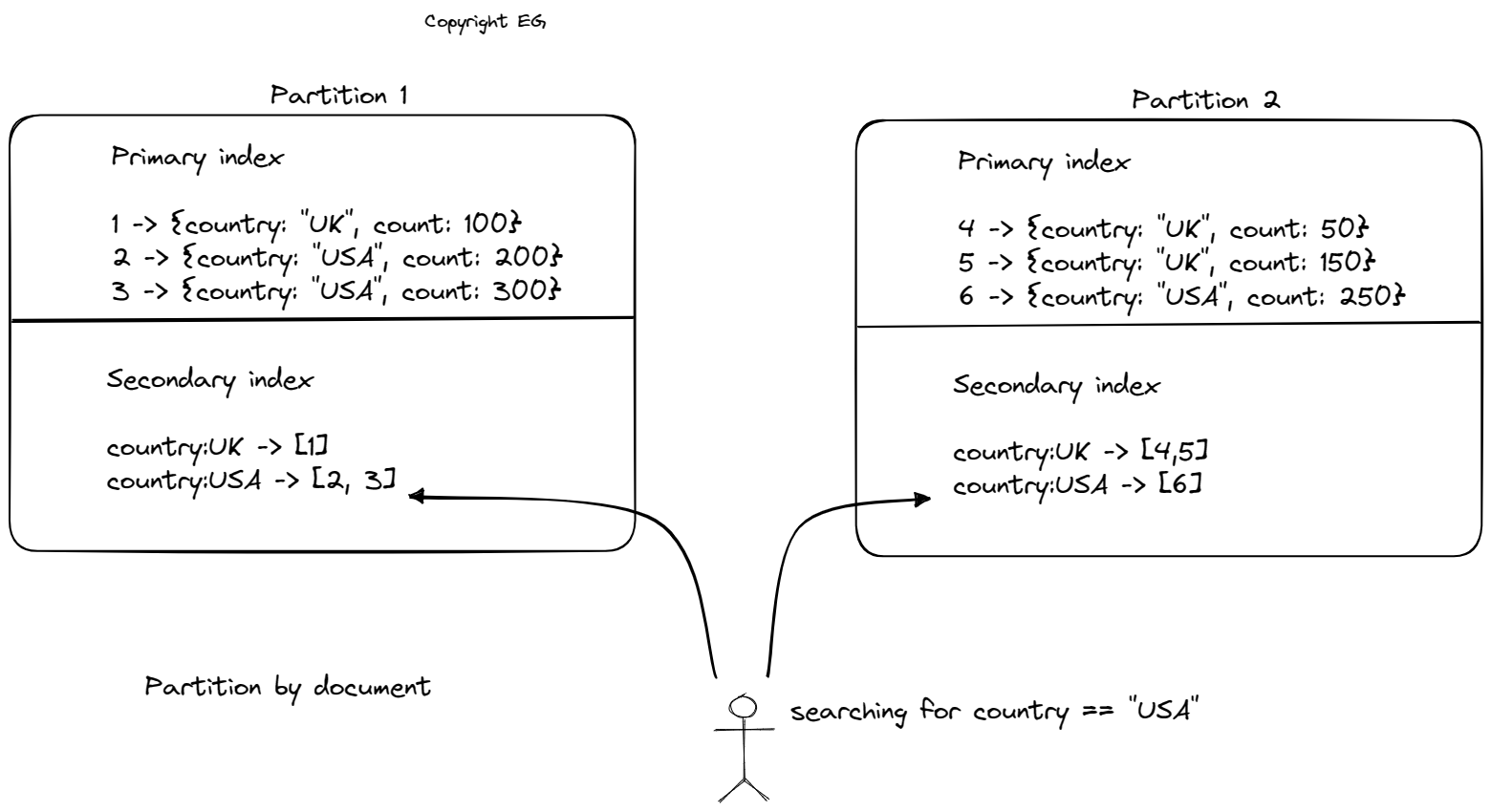
In the first approach, each partition maintains its own secondary index covering only the documents in that partition, also known as a local index. This means that a query must be sent to all partitions and the results must be combined, a process known as scatter/gather. This approach is used by databases such as MongoDB, Riak, Cassandra, Elasticsearch, SolrCloud, and VoltDB, but it can be prone to tail latency amplification (slowest request causing overall delays).
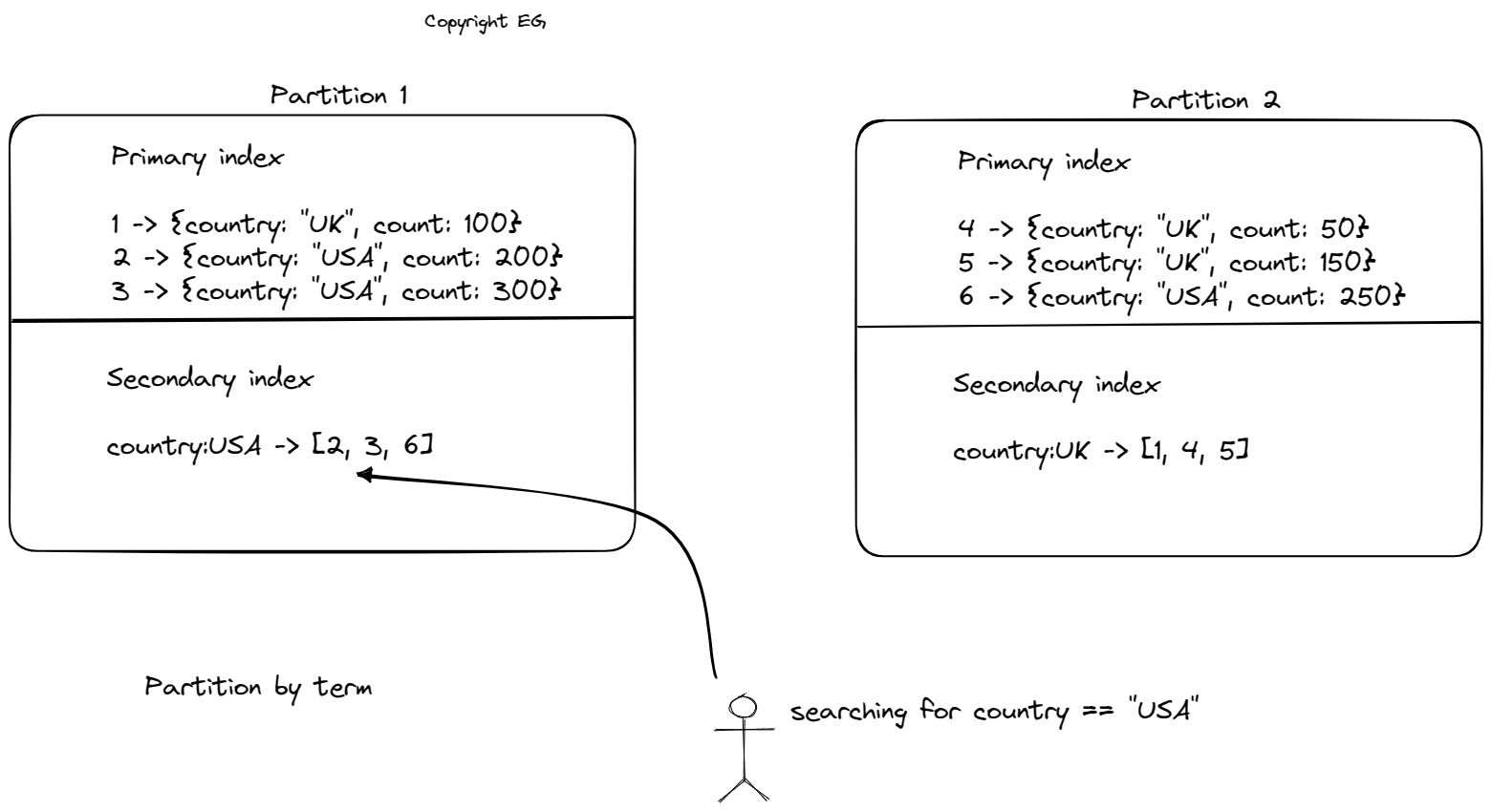
The second approach involves creating a global index that covers data in all partitions. This global index must also be partitioned to avoid becoming a bottleneck. This approach is known as term-partitioning because the search term determines the partition of the index. The advantage of this approach is that it can make reads more efficient by allowing clients to only request the partition containing the desired term. However, writes are slower and more complex with a global index.
Rebalancing Partitions
Rebalancing is the process of moving load from one node to another within a cluster. There are several strategies for rebalancing data in a sharded system:
- Hash mod n: This approach assigns keys to nodes based on a hash of the key modulo the number of nodes. The problem with this approach is that if the number of nodes changes, most of the keys will need to be moved to different nodes.
- Fixed number of partitions: This approach involves creating many more partitions than there are nodes and assigning several partitions to each node. If a new node is added to the cluster, a few partitions can be stolen from every existing node until the partitions are evenly distributed again. This approach is used by databases such as Riak, Elasticsearch, Couchbase, and Voldemport.
- Dynamic partitioning: The number of partitions in this approach adapts to the total data volume. An empty database starts with a single partition, which is split into smaller partitions as the dataset grows. This approach is used by databases such as HBase and MongoDB, which allow an initial set of partitions to be configured.
- Partitioning proportionally to nodes: This approach, used by databases such as Cassandra and Ketama, involves keeping the number of partitions proportional to the number of nodes and maintaining a fixed number of partitions per node. This helps to keep the size of each partition fairly stable.
Request Routing
Service discovery, or the process of identifying the location of specific data or services within a distributed system, is a common problem in sharded systems. There are several approaches to solving this problem, including allowing clients to contact any node and handle the request directly or forwarding it to the appropriate node, using a routing tier that acts as a partition-aware load balancer, or making clients aware of the partitioning and assignment of partitions to nodes.
In order to keep track of changes in the assignment of partitions to nodes, many distributed data systems rely on a separate coordination service such as ZooKeeper. Each node registers itself in ZooKeeper, which maintains the authoritative mapping of partitions to nodes. The routing tier or partition-aware client can then subscribe to this information in ZooKeeper. Other systems, such as MongoDB, use their own config server for this purpose, while Cassandra and Riak use a gossip protocol (spreading from node to node like a gossip).
Summary
There are two primary ways to partition data: key range partitioning and hash partitioning. In key range partitioning, keys are sorted and a partition is responsible for all keys within a certain range. This allows for efficient range queries, but can result in hot spots if the keys are accessed frequently in a contiguous order. To address this issue, the range can be dynamically split into smaller ranges to rebalance the load. On the other hand, hash partitioning involves applying a hash function to the keys and assigning a range of hashes to a partition. While this method does not preserve the ordering of the keys, it can result in a more evenly distributed load. In hash partitioning, it is common to create a fixed number of partitions in advance and assign multiple partitions to each node. Dynamic partitioning can also be used, allowing entire partitions to be moved between nodes as needed.
In addition to partitioning data, we also discussed how partitioning relates to secondary indexes. There are two approaches to partitioning secondary indexes: document-partitioned indexes (also known as local indexes) and term-partitioned indexes (also known as global indexes). In document-partitioned indexes, the secondary index is stored in the same partition as the primary key and value. This means that only a single partition needs to be updated when a document is written, but a read of the secondary index requires gathering data from all partitions. On the other hand, term-partitioned indexes involve partitioning the secondary index separately using the indexed values. This means that an entry in the secondary index may include records from all partitions of the primary key. When a document is written, multiple partitions of the secondary index may need to be updated, but a read can be served from a single partition.