Replication

Replication
There are several reasons why you might want to replicate data:
- To keep data geographically close to your users, which can reduce latency and improve the performance of your system.
- To increase availability, which can help ensure that your system remains accessible even if one or more of your data nodes fail.
- To increase read throughput, which can help your system handle a higher volume of requests.
One of the challenges of data replication is handling changes to replicated data. There are several popular algorithms for replicating changes between nodes, including single-leader, multi-leader, and leaderless replication.
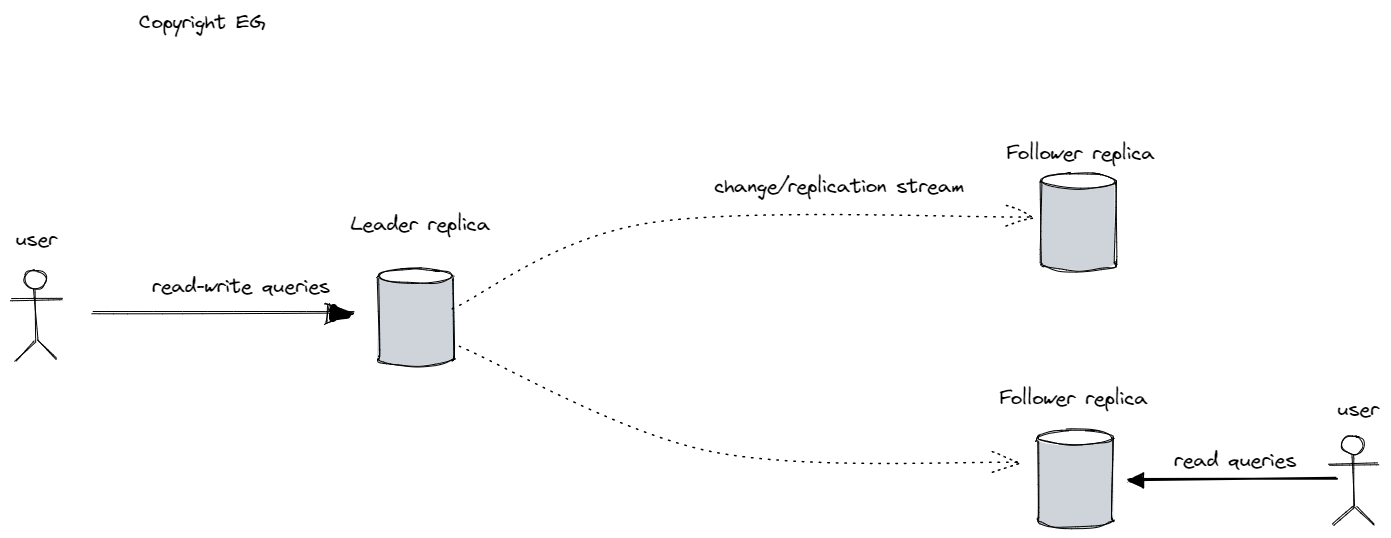
Leaders and followers
In a replicated database, each node that stores a copy of the database is called a replica. In order to maintain consistency across all replicas, every write to the database must be processed by every replica.
The most common approach to achieving this is through leader-based replication, also known as active/passive or master-slave replication. In this model, one of the replicas is designated the leader (or master, primary) and all write requests must be sent to the leader. The other replicas are known as followers (or read replicas, slaves, secondaries, or hot stanbys) and receive updates from the leader as part of a replication log or change stream. Reads can be performed on the leader or any of the followers, but writes are only accepted on the leader.
Examples of databases that use leader-based replication include MySQL, Oracle Data Guard, SQL Server’s AlwaysOn Availability Groups, MongoDB, RethinkDB, Espresso, Kafka, and RabbitMQ.
Synchronous Versus Asynchronous Replication
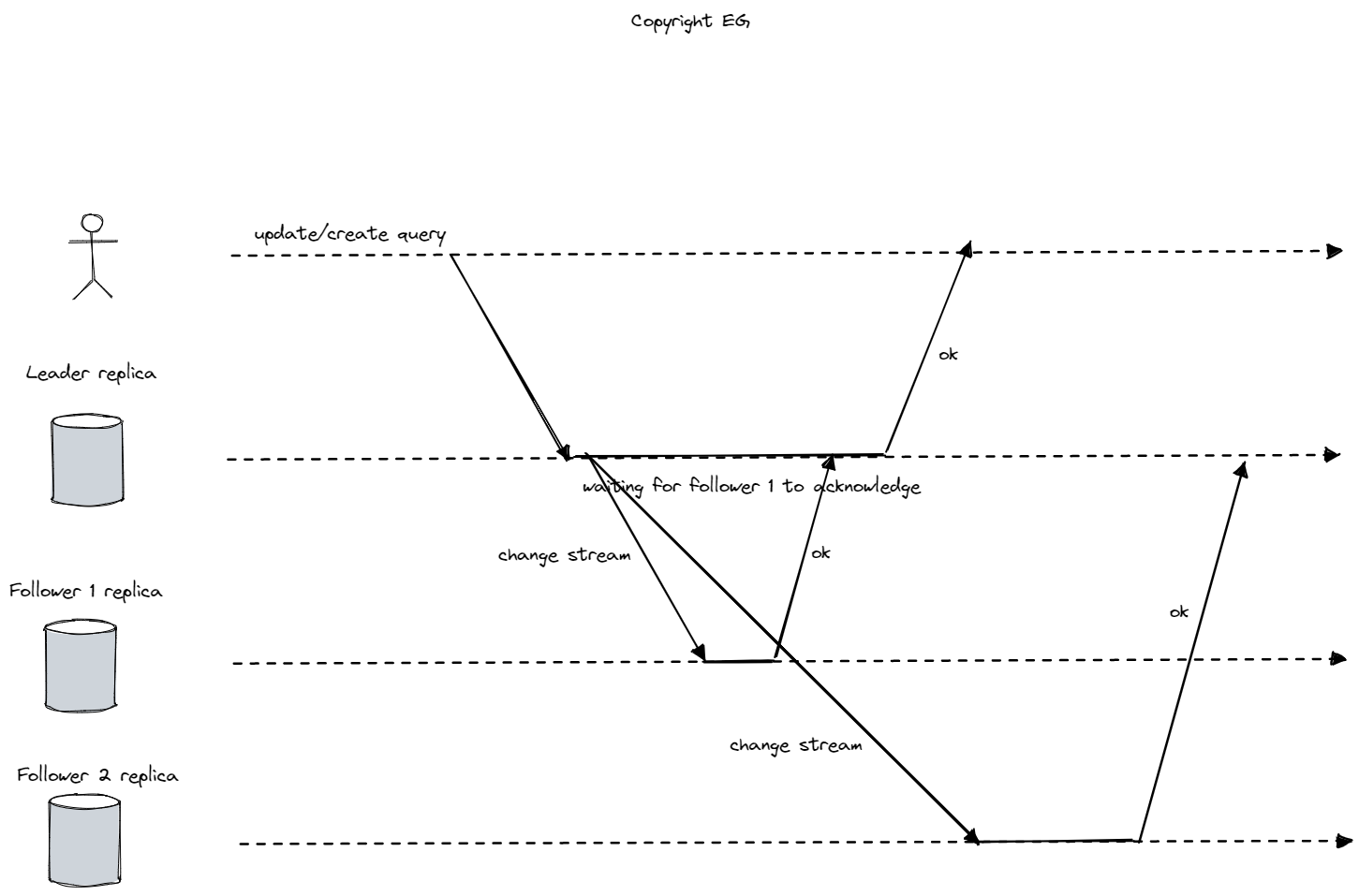
Synchronous replication is a type of data replication where the follower must acknowledge the receipt of each write from the leader before the leader considers the write to be complete. This guarantees that the follower always has an up-to-date copy of the data that is consistent with the leader. However, if the synchronous follower is unavailable or does not respond in time, the leader cannot process the write.
In practice, it is not practical for all followers in a replicated database to be synchronous, as this would limit the system’s availability. Instead, leader-based replication is often asynchronous, which means that the leader does not wait for the followers to acknowledge each write. The advantage of this approach is that the leader can continue processing writes even if one or more followers are unavailable. However, writes are not guaranteed to be durable in this case, as they may be lost if the leader fails before they are replicated to the followers.
In some systems, only one of the followers is synchronous, while the others are asynchronous. This is sometimes called semi-synchronous replication, and it provides a balance between availability and durability by ensuring that there is at least one up-to-date replica of the data at all times.
Setting up New followers
In order to set up a new follower in a replicated database, simply copying the data files from the leader is not sufficient. Instead, the process typically involves taking a snapshot of the leader’s database, copying that snapshot to the follower node, and then having the follower request and process any data changes that have occurred since the snapshot was taken. This ensures that the follower has an up-to-date copy of the data that is consistent with the leader. Once the follower has caught up by processing the backlog of changes, it can begin participating in the replication process.
In many cases, this process can be performed without downtime, allowing the new follower to be added to the system without interrupting its availability. However, this may not be possible in all cases, and some systems may require a brief period of downtime in order to set up a new follower.
Failures
In a replicated database, there are two main scenarios that can require the system to recover from a failure:
- Follower failure
- Leader failure.
In the case of follower failure, the follower can typically recover by connecting to the leader and requesting all of the data changes that occurred during the time when the follower was disconnected. This process is known as catchup recovery, and it allows the follower to catch up with the leader and resume participating in the replication process.
In the case of leader failure, one of the followers must be promoted to be the new leader. This process, known as failover, typically involves reconfiguring the clients to send their write requests to the new leader and reconfiguring the followers to consume data changes from the new leader.
Automatic failover is a process that can be performed by the database software to handle leader failure without requiring human intervention. It typically involves determining that the leader has failed, choosing a new leader from among the available followers, and reconfiguring the system to use the new leader. However, automatic failover is not without risks, as it can lead to data loss or corruption if not implemented carefully.
One potential problem with automatic failover is that if asynchronous replication is used, the new leader may have received conflicting writes from the old leader during the time when the system was in a “split brain” state (i.e., when two nodes both believed that they were the leader). Another problem is that the system must decide when the old leader is considered “dead” and can be safely demoted to a follower, which can be difficult to determine in some cases. For these reasons, some database administrators prefer to perform failovers manually, even if the database software supports automatic failover.
Implementation of Replication Logs
There are several different approaches to replicating data in a database, each with its own advantages and disadvantages.
One approach is called statement-based replication, where the leader logs every SQL statement (e.g., INSERT, UPDATE, DELETE) that modifies the data and sends it to its followers. This approach is simple to implement, but it has several drawbacks. For example, non-deterministic functions like NOW() or RAND() will generate different values on the followers, and statements that depend on existing data (e.g., auto-increments) must be executed in the same order on each replica. In order to address these problems, the leader can replace any non-deterministic function with a fixed return value in the logged statements.
Another approach is called write-ahead log (WAL) shipping, where the leader logs all writes to the database as a sequence of bytes and sends this log to the followers. This approach is used in databases like PostgresSQL and Oracle, and it has the advantage of being decoupled from the storage engine, which makes it easier to maintain backwards compatibility. However, the log describes the data at a very low level (e.g., which bytes were changed in which disk blocks), which makes it difficult for external applications to parse.
A third approach is called logical (row-based) log replication, where the leader logs each write to the database at the granularity of a row. For example, an INSERT statement will be logged as the new values of all columns in the inserted row, while an UPDATE statement will be logged as the information needed to uniquely identify the updated row and the new values of its columns. This approach is used in MySQL binlog, and it has the advantage of being easier for external applications to parse, which makes it useful for data warehouses, custom indexes, and caches. However, it can have higher overhead than other approaches and is more prone to bugs.
A fourth approach is called trigger-based replication, where custom application code is registered as a trigger that is automatically executed whenever a data change occurs. This code can log the change in a separate table, which can then be read by an external process to replicate the data. This approach is more flexible than other methods, but it can also be slower and more error-prone.
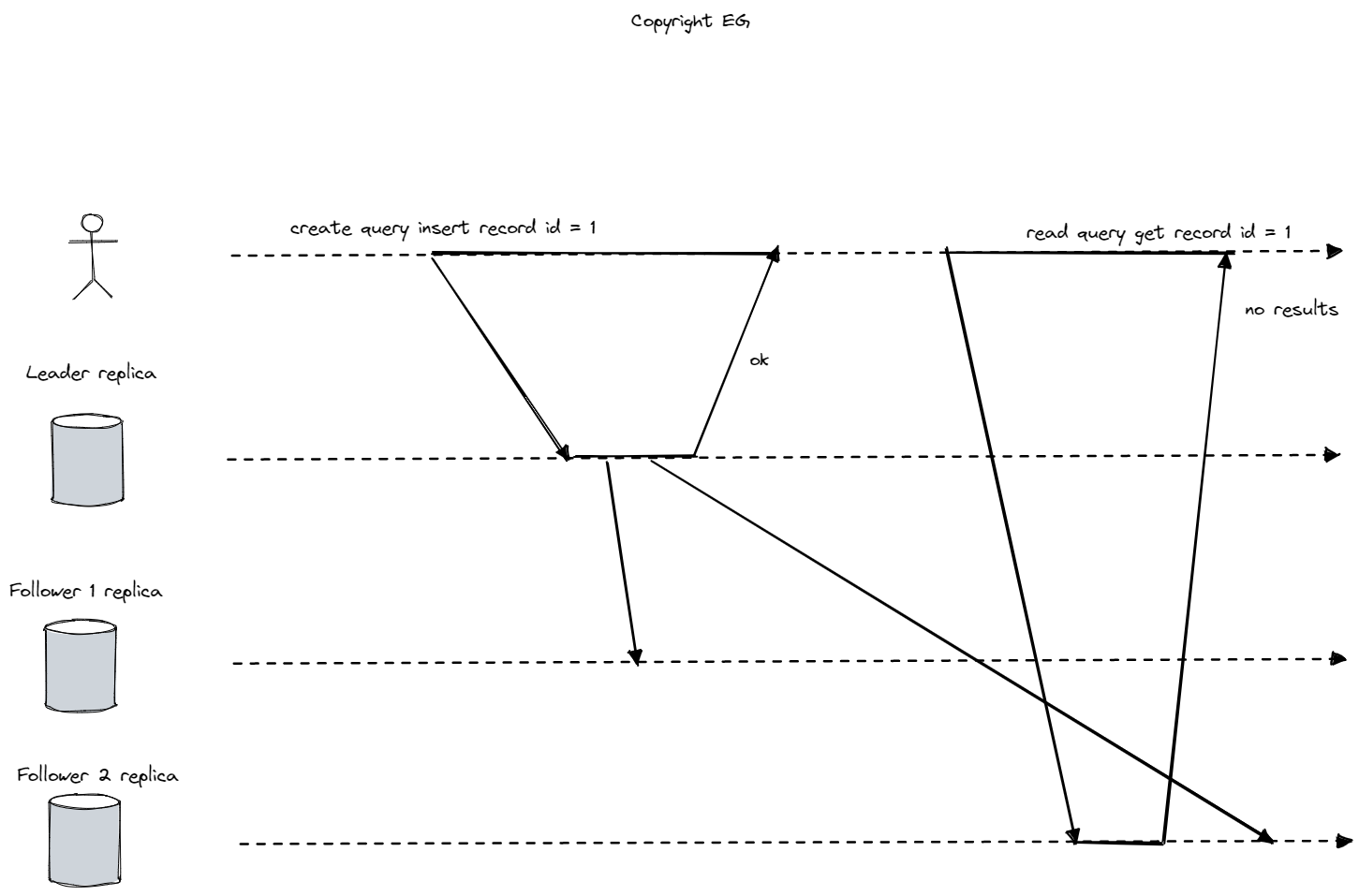
Problems with Replication Lag
Replication is used for many reasons, including ensuring reliability and increasing scalability. In a read-scaling architecture, adding more followers can help handle read-only requests, but this only works well with asynchronous replication. Synchronous replication can be unreliable with a large number of nodes. However, asynchronous replication can lead to inconsistencies in the database due to replication lag, which can range from a few seconds to several minutes. To solve these problems, it is important to carefully monitor and manage the replication process.
Reading Your Own Writes
Read-after-write consistency, also known as read-your-writes consistency, is a guarantee that a user will always see any updates they have made when they reload a page. There are several ways to implement this:
- When reading something that a user may have modified, read it from the leader. For example, user profile information on a social network is typically only editable by the owner, so it would make sense to always read the user’s own profile from the leader.
- Track the time of the latest update, and for one minute after the last update, make all reads from the leader. This way, you can ensure that the replica serving any reads for that user reflects updates at least until that timestamp.
- The client can remember the timestamp of the most recent write, and the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp.
If your replicas are distributed across multiple datacenters, then you will need to route requests to the datacenter that contains the leader. Additionally, if the same user is accessing your service from multiple devices, you may want to provide cross-device read-after-write consistency.
There are some additional issues to consider when implementing read-after-write consistency:
- Remembering the timestamp of the user’s last update becomes more difficult when using a distributed system. You may need to centralize the metadata to make this possible.
- If replicas are distributed across datacenters, there is no guarantee that connections from different devices will be routed to the same datacenter. You may need to implement a system for routing requests from all of a user’s devices to the same datacenter to ensure consistency.
Monotonic Reads
Due to replication lag, it is possible for a user to see things moving backward in time. This can happen when a follower falls behind and an old value is returned when the user reads data. To avoid this, it is important to ensure that each user always makes their reads from the same replica. This replica can be chosen based on a hash of the user’s ID. If the chosen replica fails, the user’s queries will need to be rerouted to another replica. This way, monotonic reads can be ensured, meaning that if one user makes several reads in sequence, they will not see time go backward.
Consistent Prefix Reads
Consistent prefix reads ensure that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order. This can be a problem in partitioned (sharded) databases, as there is no global ordering of writes. To solve this problem, it is important to make sure that any writes that are casually related to each other are written to the same partition. This will help ensure that the writes are seen in the correct order when they are read.
Replication lag solutions
When working with eventually consistent systems, it is important to consider how the application will behave if the replication lag increases significantly. If this would result in a poor user experience, it may be necessary to design the system to provide stronger guarantees, such as read-after-write consistency. Ignoring the fact that replication is asynchronous and pretending that it is synchronous can lead to problems in the future.
Application developers can provide stronger guarantees than the underlying database by performing certain kinds of reads on the leader. However, this can be complex and error-prone. It would be better if developers could rely on the database to handle these issues, which is where transactions come in. Transactions are a way for a database to provide stronger guarantees, making it easier for the application to be simpler and more reliable.
While single-node transactions have been around for a long time, many systems have abandoned them in favor of distributed databases, citing performance and availability concerns. Some argue that eventual consistency is inevitable in scalable systems. However, this is not necessarily the case, and it is important to carefully consider the trade-offs and design a system that provides the appropriate level of consistency for the specific use case.
Multi-leader Replication
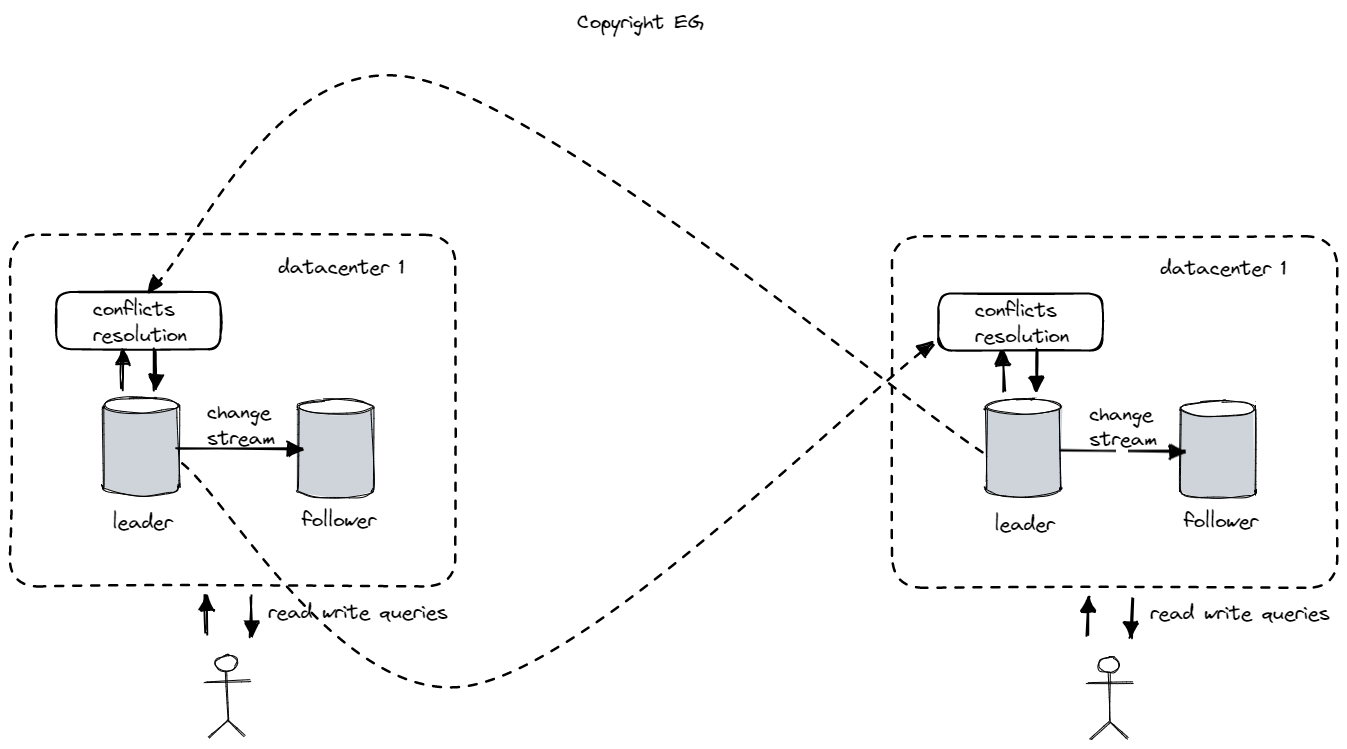
Single leader-based replication has the disadvantage of only allowing one node to accept writes. To overcome this limitation, it is possible to use multi-leader or master-master replication, which allows multiple nodes to accept writes simultaneously. Each leader acts as a follower to the other leaders, so that changes can be replicated between them.
Multi-leader replication is not typically useful within a single datacenter, but it can be useful in a multi-datacenter setup. In this case, each datacenter can have its own leader, and changes can be replicated asynchronously between the datacenters. This can improve performance, as writes are processed locally and only replicated asynchronously, rather than being sent over the internet to a single leader. It can also improve tolerance of datacenter outages and network problems, as each datacenter can continue to operate independently from the others.
Multi-leader replication can be implemented using tools like Tungsten Replicator for MySQL, BDR for PostgreSQL, or GoldenGate for Oracle. However, it is important to be aware of potential pitfalls, such as issues with autoincrementing keys, triggers, and integrity constraints. For this reason, multi-leader replication is often considered dangerous territory and avoided if possible.
Clients with offline operation
If an application needs to continue working while offline, it may be necessary to use multi-leader replication on each device that has a local database. This allows each device to act as a leader and ensures that changes can be replicated asynchronously between devices when they are reconnected to the internet. CouchDB is designed for this type of operation, where devices can operate independently and then synchronize their data when they are able to connect. This can be useful for applications like calendars, where users need to be able to make changes on their devices even when they are not connected to the internet.
Collaborative editing
Real-time collaborative editing applications allow multiple users to edit a document simultaneously. Examples of this include Etherpad and Google Docs. When a user makes changes to a document, these changes are applied to their local replica and then replicated asynchronously to the server and any other users who are editing the document.
To avoid conflicts when multiple users are editing the same document, it is necessary to lock the document before allowing a user to edit it. This ensures that only one user can make changes at a time, preventing conflicts. However, this can also slow down collaboration, as users must wait for the lock to be released before they can make changes.
Alternatively, you can make the unit of change very small (such as a single keystroke) and avoid locking the document altogether. This allows for faster collaboration, but it also increases the likelihood of conflicts occurring. It is up to the application designers to decide which approach is more appropriate for their specific use case.
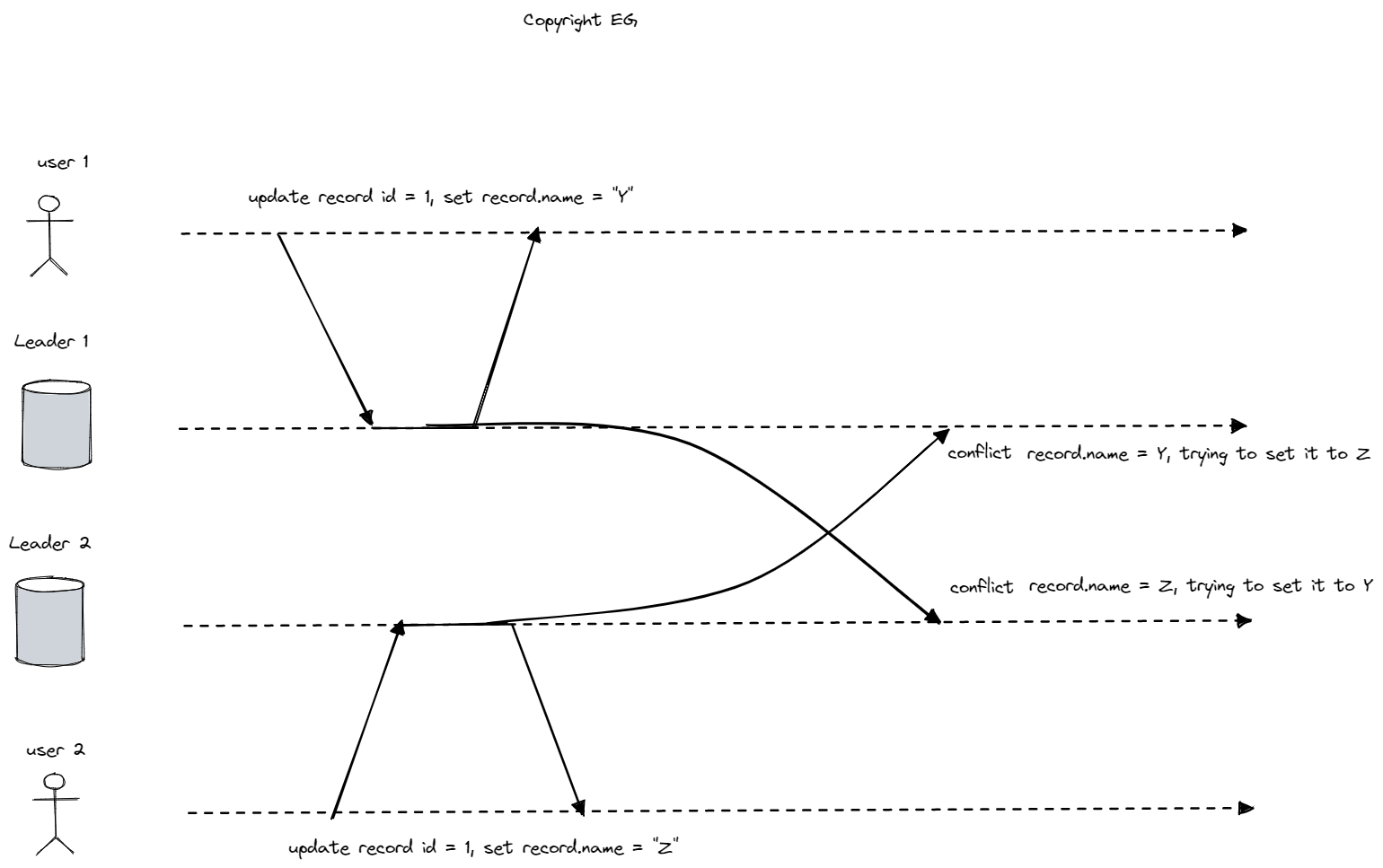
Handling Write Conflicts
One of the biggest challenges with multi-leader replication is dealing with conflicts when multiple nodes try to write to the same data simultaneously. This is not a problem in single-leader databases, as the second writer can be blocked and made to wait until the first writer has completed their write. In a multi-leader setup, both writes may be successful, and the conflict is only detected asynchronously at a later time.
If you want to avoid conflicts, one strategy is to ensure that all writes for a particular record go through the same leader. This way, conflicts cannot occur. For example, in an application where a user can edit their own data, you can route requests from a particular user to the same datacenter and use the leader in that datacenter for reading and writing.
When conflicts do occur in a multi-leader database, it is necessary to resolve them in a way that ensures that all replicas arrive at the same final value when all changes have been replicated. There are several ways to achieve this:
- Last write wins (LWW): Each write is given a unique ID (such as a timestamp, random number, UUID, or hash of the key and value), and the write with the highest ID is chosen as the winner. This is simple to implement, but it is prone to data loss.
- Replica priority: Each replica is given a unique ID, and writes that originated at a higher-numbered replica always take precedence. This approach also implies data loss.
- Merge values: Some way of merging the conflicting values together is needed.
- Record the conflict: The conflict is recorded and resolved by application code at a later time (perhaps by prompting the user).
- Custom conflict resolution: Multi-leader replication tools often allow you to write custom conflict resolution logic using application code. This can be called as soon as the database system detects a conflict in the log of replicated changes, or it can be called on read, when multiple versions of the data are returned to the application. CouchDB uses this approach.
It is important to carefully consider the trade-offs and choose the appropriate conflict resolution strategy for your specific use case.
There is ongoing research on ways to automatically handle conflicts that occur when multiple people concurrently modify data:
- Conflict-free replicated datatypes (CRDTs), which are data structures that can be edited concurrently by multiple users and automatically resolve conflicts in a logical way. CRDTs are available for sets, maps, ordered lists, counters, and more. Some CRDTs have been implemented in the Riak 2.0 database system.
- Mergeable persistent data structures, which keep track of history like the Git version control system and use a three-way merge function to resolve conflicts.
- Operational transformation is a conflict resolution algorithm used in collaborative editing applications such as Etherpad and Google Docs, specifically designed for concurrent editing of ordered lists of items like the characters in a text document.
Multi-Leader Replication Topologies
A replication topology is the arrangement of nodes in a system that determines how data is replicated between them. In an all-to-all topology, every node sends its writes to every other node. This provides good fault tolerance because messages can travel along multiple paths, but can also lead to problems if some network links are faster than others, causing some messages to “overtake” others. To solve this problem, version vectors can be used to order events correctly. In a circular topology, each node receives writes from one node and sends them to another. In a star topology, a central node sends writes to all other nodes. Both of these topologies can suffer from a single point of failure if a node fails and interrupts the flow of replication messages. To avoid infinite replication loops, nodes in these topologies are given unique identifiers, and writes are tagged with the identifiers of the nodes they have passed through. PostgresSQL BDR and Tungsten Replicator for MySQL do not provide causal ordering of writes or detect conflicts.
Leaderless Replication
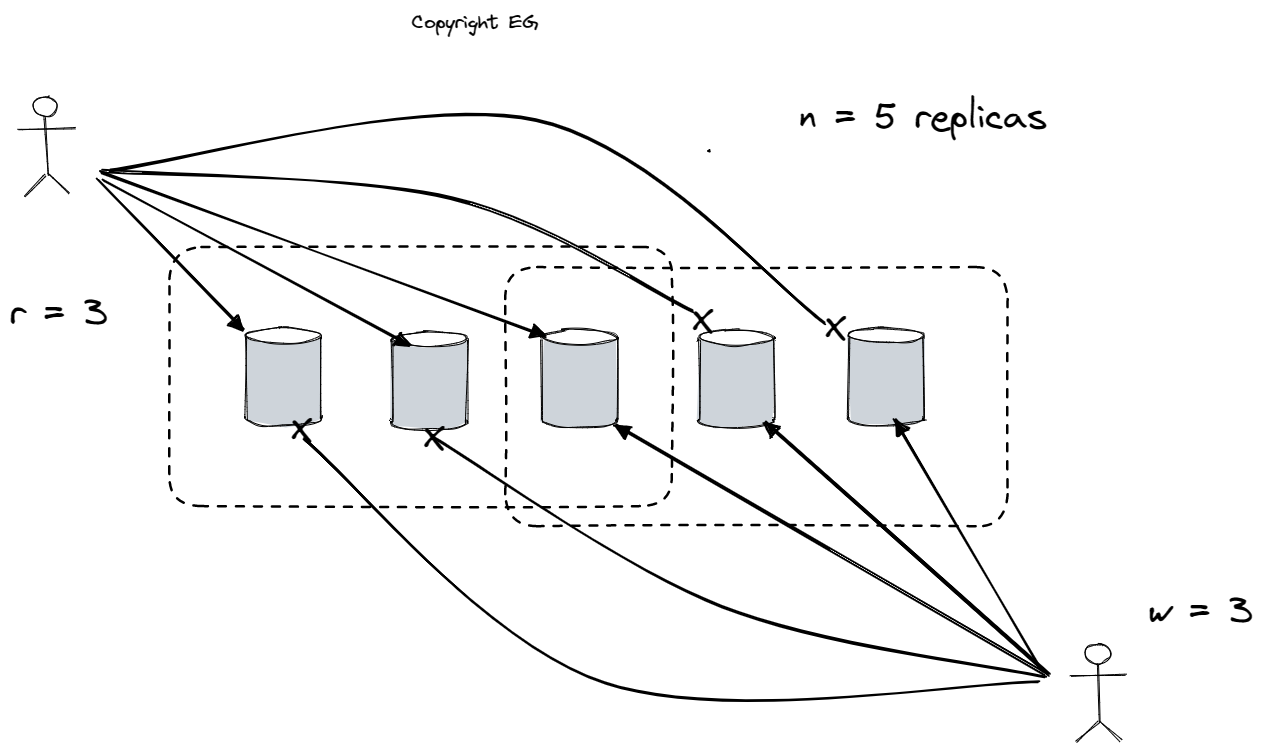
In a database system with leaderless configuration, clients can directly send write requests to any replica. This type of system is similar to Amazon’s Dynamo datastore and includes databases such as Riak, Cassandra, and Voldemort. When a client makes a read request, it is sent to multiple nodes in parallel and version numbers are used to determine which response is more current. Eventually, all replicas will have copies of all the data. If a node becomes unavailable and later comes back online, it can catch up by using a process called read repair, in which the client writes any newer values back to the stale replica, or an anti-entropy process, which constantly compares data between replicas and copies any missing data from one replica to the other. To ensure that read and write operations are successful, a quorum of w nodes must confirm each write and at least r nodes must be queried for each read, as long as w + r > n, where n is the number of replicas. The values of r and w are known as quorum reads and quorum writes, and they represent the minimum number of votes required for the read or write to be considered valid.
In many leaderless database systems, it is common to choose n to be an odd number, typically 3 or 5, and set w and r equal to (n + 1)/2 (rounded up). This type of configuration is called a sloppy quorum, and it can have some limitations. For example, the w writes may end up on different nodes than the r reads, so there is no longer a guaranteed overlap between the nodes that received the write and those that were queried for the read. Concurrent writes can also be a problem, as it may not be clear which write happened first. In this case, the only safe solution is to merge the writes. Clock skew can also cause writes to be lost. If a write occurs concurrently with a read, the write may only be reflected on some of the replicas, and if a write succeeds on some replicas but fails on others, it may not be rolled back on the replicas where it succeeded. This can lead to situations where reads may or may not return the value from the failed write. Additionally, if a node carrying a new value fails and its data is restored from a replica carrying an old value, the number of replicas storing the new value may not meet the quorum condition.
Leaderless replication is a database configuration that may be appealing for use cases that require high availability and low latency and can tolerate occasional stale reads. In this type of system, it may be difficult for clients to connect to all database nodes during a network interruption. One option is to return errors for all requests that cannot reach the required quorum of w or r nodes. Another option is to accept writes anyway and write them to nodes that are reachable but not among the n nodes that are designated as the “home” nodes for a particular value. This is known as a sloppy quorum and it can increase write availability by allowing the database to accept writes as long as any w nodes are available. However, it also means that you cannot be sure to read the latest value for a key, as it may have been temporarily written to nodes outside of the n “home” nodes. Once the network interruption is fixed, any writes that were accepted during the interruption are sent to the appropriate “home” nodes using a process called hinted handoff.
Detecting Concurrent Writes
In order to become eventually consistent, replicas in a database system need to converge towards the same value. This requires careful handling of conflicts, which can occur when multiple writes are made to the same data concurrently. One approach to conflict resolution is called last write wins, which involves discarding concurrent writes and keeping only the most recent write, based on a timestamp. While this approach may be acceptable in some situations, such as when caching data, it can result in data loss and is not suitable for applications where preserving all data is important. Another approach to handling concurrency is to consider the “happens-before” relationship between operations. This involves defining whether one operation happened before another operation or if they are concurrent. This can help to ensure that data is consistently handled and that conflicts are resolved in a way that maintains the integrity of the data.
Capturing the Happens-before Relationship
In a database system that uses version numbers to track changes to data, the server can determine whether two operations are concurrent by looking at the version numbers:
- The server maintains a version number for each key and increments it every time the key is written.
- When a client reads a key, the server returns all values that have not been overwritten, as well as the latest version number.
- A client must read a key before writing to it and must include the version number from the prior read when making a write request.
- The client must also merge together all values that it received in the prior read.
- When the server receives a write request with a particular version number, it can overwrite all values with that version number or lower, but it must keep all values with a higher version number.
In a database system that handles concurrent operations, no data is silently dropped, but clients must do some extra work to clean up by merging the concurrently written values, also known as siblings. Merging siblings is similar to the problem of conflict resolution in a multi-leader replication system, and a simple approach is to use a last write wins strategy based on version numbers or timestamps. However, this may not always be the best solution, as it can result in data loss. In some cases, it may be necessary to do something more intelligent in application code to avoid losing data. One of popular approaches is Conflict-free Replicated Data Types (CRDTs).