Storage and Retrieval

Storage and Retrieval
It’s an oversimplification but in essence database has to do only two things:
- if you give it data, it should store it
- if you ask again for the data, it should give the data back.
So we could build the simplest database ever by using only two Bash functions:
#!/bin/bash
db_set () {
echo "$1,$2" >> dummydatabase
}
db_get () {
grep "^$1," dummydatabase | sed -e "s/^$1,//" | tail -n 1
}
Of course real database systems have to deal with many more things such handling errors, reclaiming disks, concurrency…
But from the fundamental point of view these two functions keep the log, write to it key/value pairs and retrieve the last occurrence of the key with corresponding value. Generally you should look at log as an append-only sequence of records. The db_set function performs well since it only writes to our log file, but our db_get is terrible in context of getting stored data since it scans all the records in log to find the last occurrence of the key making in O(n) traversal which is of course not good enough for real database systems. The next section will go into details on how use index to speed up the retrieval of data. You can think of an index as an auxiliary structure derived from primary data that speeds up the read operation. It’s important to note that index is a simple example of pushing the boundary between read and write paths (in other words we gain on read queries, but lose at writes).
Hash indexes
A key-value store is similar to a dictionary in that it uses a hash map to associate keys with values. In a key-value store, data is stored in a file, and an in-memory hash map is used to keep track of the location of each key in the file. When a new key-value pair is added to the store, the hash map is updated to reflect the location of the data in the file. Storage engines like Bitcask, which is used in Riak as default storage engine, are suitable for situations where the values associated with each key are frequently updated. To prevent the file from growing too large, the log can be broken into segments (when they reach certain size) and compaction can be performed to remove duplicate keys and keep only the most recent updates. Merging and compaction can be done in a background thread, and once the process is complete, the old segment files can be deleted. Each segment has its own in-memory hash map, and to find a value for a key, the most recent segment is checked first, followed by the second-most recent segment, and so on. The merging process helps to keep the number of segments small, so that lookups are efficient. Simple example of merging and compaction is show in the image below:
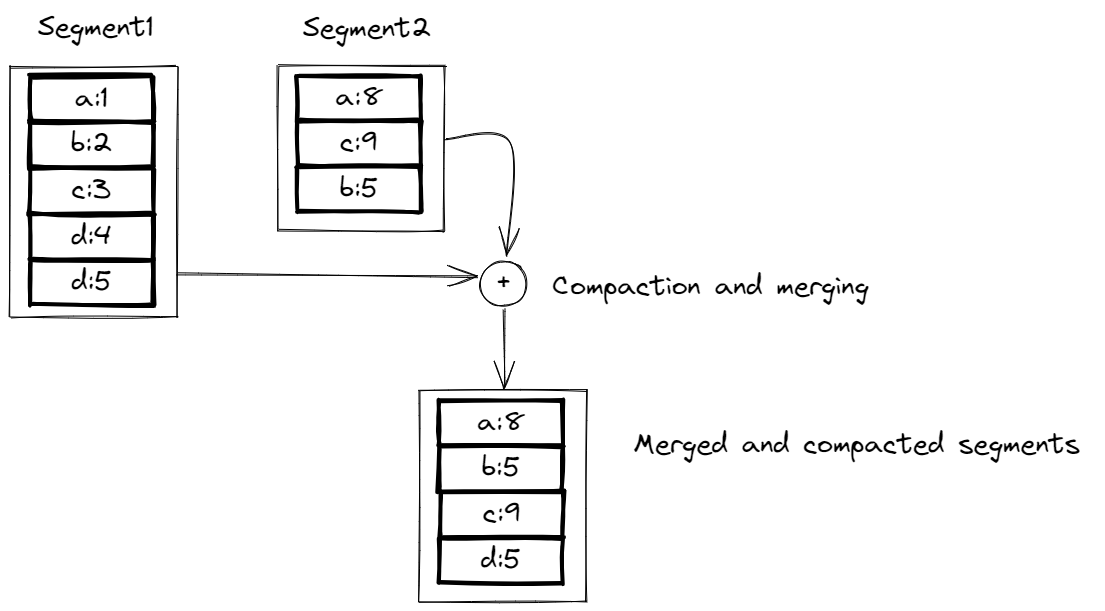
When implementing a key-value store, there are several important issues to consider. One issue is the file format, which can be binary for simplicity. Another issue is how to delete records, which can be done by appending a special “tombstone” record to the data file to indicate that previous values should be discarded during the merging process. Crash recovery is also important, as the in-memory hash maps will be lost if the database is restarted. Bitcask speeds up recovery by storing snapshots of each segment hash map on disk. It is also important to handle partially written records, which can occur if the database crashes. Bitcask includes checksums to detect and ignore corrupted parts of the log. Finally, concurrency control is necessary, as writes must be appended to the log in a sequential order. A common implementation is to use a single writer thread, while segments can be read concurrently by multiple threads because they are immutable.
Using an append-only design for a key-value store has several benefits:
- Appending and segment merging are sequential write operations, which are much faster than random writes, especially on magnetic spinning disks.
- This design also makes concurrency and crash recovery simpler.
- Merging old segments avoids file fragmentation over time.
While a hash table is useful for storing and accessing data in a key-value store, it also has some limitations. The main limitation is that the hash table must fit in memory, which can be a problem if there are a large number of keys. It is also difficult to make an on-disk hash map perform well. Additionally, range queries are not efficient with a hash table, which can make it difficult to retrieve data within a certain range.
SSTables and LSM-Trees
In order to improve the performance of a key-value store, we can introduce a new requirement for segment files: the sequence of key-value pairs must be sorted by key. This type of segment file is called a Sorted String Table, or SSTable. To ensure that each key only appears once in each merged segment file (which is already ensured by compaction), we require that the keys are sorted. SSTables have several advantages over log segments with hash indexes:
- For example, merging segments is simple and efficient because we can use algorithms like mergesort. When multiple segments contain the same key, we can keep the value from the most recent segment and discard the values in older segments.
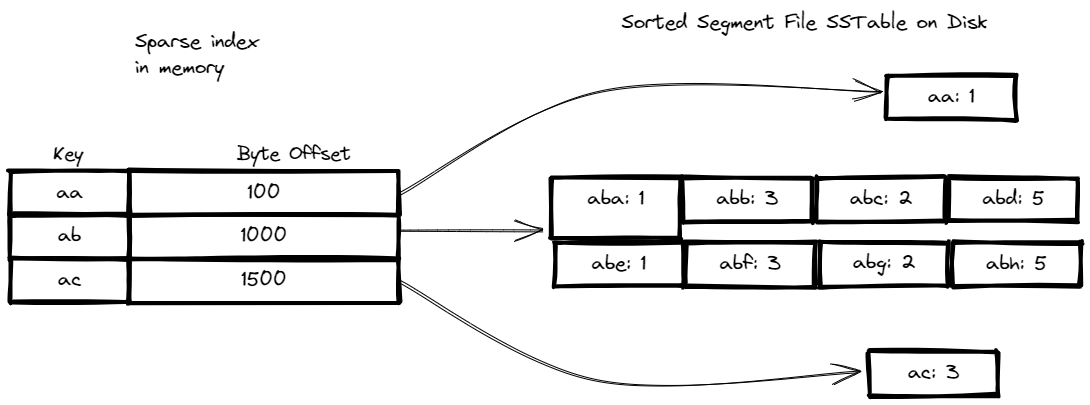
- Additionally, we no longer need to keep an in-memory index of all the keys, which can save memory. Instead, we can use an in-memory index of the offsets for some of the keys, and use this index to find the location of a particular key in the segment file. (e.g we know that
bis betweenaandcwe can jump froma(using the offset) and read until we hitcor findb) - Since read requests typically need to scan over several key-value pairs in a range, we can group these records into a block and compress it before writing it to disk, which can save disk space.
To ensure that data is sorted in a key-value store, we can use a data structure like a red-black tree or AVL tree. With these structures, we can insert keys in any order and read them back in sorted order. When a write request is received, the key and value are added to an in-memory balanced tree structure (memtable). When the memtable reaches a certain size (e.g., a few megabytes), it is written out to disk as an SSTable file, and writes can continue to a new memtable instance. On a read request, the key is first searched for in the memtable, and if it is not found, the most recent on-disk segment is searched, followed by the next-older segment, and so on. From time to time, merging and compaction are run in the background to discard overwritten and deleted values. This helps to keep the number of on-disk segments small and ensures that read requests are efficient.
A key-value store based on the LSM-tree algorithm stores data in sorted files that are periodically merged and compacted. In order to prevent the loss of data in case of a crash, the database can keep a separate log on disk to which every write is immediately appended. This log is not in sorted order, but it serves the important purpose of restoring the memtable after a crash. When the memtable is written out to an SSTable, the log can be discarded. Storage engines that use this approach are often called LSM structure engines, and Lucene, an indexing engine for full-text search, uses a similar method for storing its term dictionary. However, the LSM-tree algorithm can be slow when looking up keys that do not exist in the database. To improve performance, storage engines often use additional Bloom filters to approximate the contents of a set. There are also different strategies for determining the order and timing of SSTable compaction and merging. Two common strategies are size-tiered and leveled compaction. LevelDB and RocksDB use leveled compaction, HBase uses size-tiered compaction, and Cassandra supports both. In size-tiered compaction, newer and smaller SSTables are successively merged into older and larger ones, while in leveled compaction, the key range is split into smaller SSTables, and older data is moved into separate “levels” to reduce the amount of disk space used.
B-trees
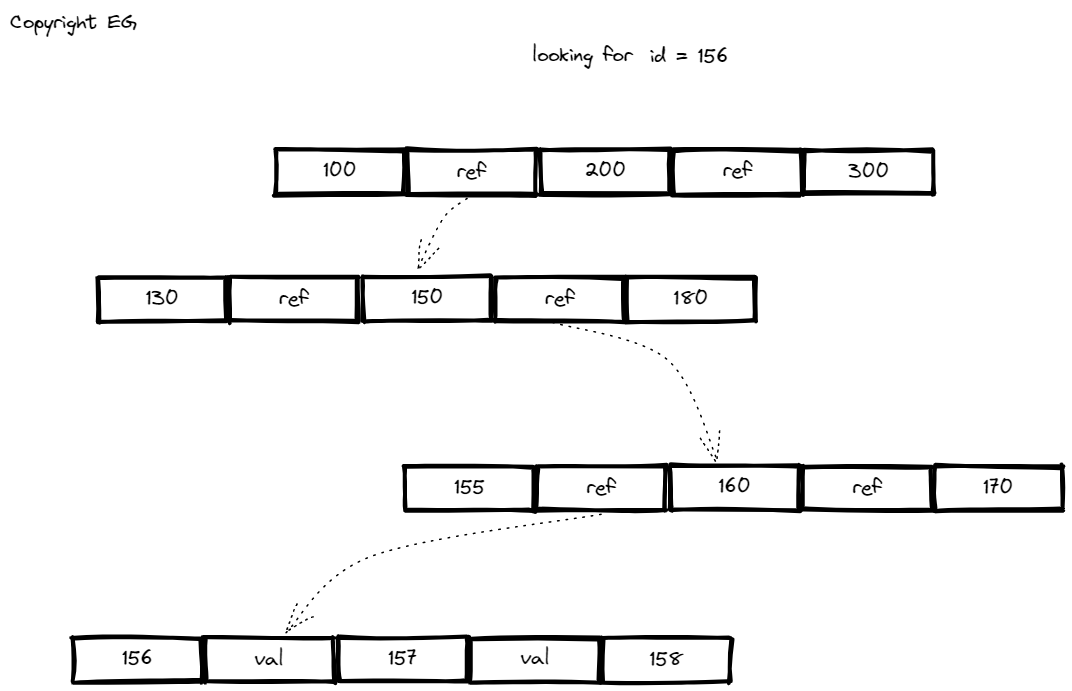
B-trees are a widely used indexing structure for key-value stores. They keep key-value pairs sorted by key, which allows for efficient key-value lookups and range queries. Unlike log-structured indexes, which break the database down into variable-size segments, B-trees break the database down into fixed-size blocks or pages, traditionally 4KB. One page is designated as the root, and searches begin from there. The page contains several keys and references to child pages. When updating the value for an existing key, the leaf page containing the key is located, the value is changed, and the page is written back to disk. To add a new key, the page is found and the key is added to it. If there is not enough free space in the page, it is split into two half-full pages, and the parent page is updated to reflect the new subdivision of key ranges. B-trees are balanced, and a B-tree with n keys always has a depth of log n. The basic underlying write operation of a B-tree is to overwrite a page on disk with new data. However, some operations, such as page splits, require multiple pages to be overwritten, which can lead to index corruption if the database crashes during the operation. To prevent this, it is common to use a write-ahead log (WAL) to track changes to the database. Concurrency control is also important when multiple threads are accessing the B-tree, and this is typically achieved by using latches (lightweight locks) to protect the tree’s internal data structures.
B-trees are a well-established indexing structure, and over the years, many optimizations have been developed to improve their performance. For example, instead of overwriting pages and using a write-ahead log (WAL) for crash recovery, some databases use a copy-on-write scheme. This involves writing modified pages to a different location and creating new versions of the parent pages that point to the new location. This approach is also useful for concurrency control. To save space in pages, keys can be abbreviated, especially in pages on the interior of the tree. Additionally, B-tree implementations often try to lay out the tree so that leaf pages are in sequential order on disk, which can improve performance for queries that need to scan over a large part of the key range. Other B-tree variants, such as fractal trees, borrow some log-structured ideas to reduce disk seeks.
B-trees and LSM-trees
LSM-trees are typically faster for writes, while B-trees are thought to be faster for reads. This is because LSM-trees have to check multiple data structures and SSTables at different stages of compaction, which can slow down read performance. LSM-trees have several advantages over B-trees, including higher write throughput, better compression, and smaller files on disk. However, they also have some downsides, such as the potential for compaction to interfere with ongoing reads and writes, and the need for more disk bandwidth as the database grows. In contrast, B-trees offer stronger transactional semantics, as each key exists in exactly one place in the index, allowing for the use of locks on key ranges.
Other Indexing Structures
We have only discussed key-value indexes, which act like a primary key index. However, there are also secondary indexes, which are similar to key-value indexes but allow for non-unique values. This can be achieved by either making each value in the index a list of matching row identifiers, or by appending a row identifier to each entry to make it unique. Secondary indexes can be easily constructed from key-value indexes.
Keeping everything in memory
In-memory databases take advantage of the durability and lower cost per gigabyte of disk storage. They are able to keep the entire database in memory, which can improve performance by avoiding the overhead of encoding in-memory data structures for writing to disk. In-memory databases can be used for both durable and non-durable data storage. When used for durable storage, the database may use a log of changes or replicas for data recovery. In-memory databases may also provide data models that are difficult to implement with disk-based indexes. Products such as VoltDB, MemSQL, and Oracle TimesTime are examples of in-memory databases.
Full-text search and fuzzy indexes
Indexes do not allow for searching for similar keys, such as misspelled words. This type of fuzzy querying requires different techniques, such as those used in full-text search engines. These engines are able to handle synonyms, grammatical variations, and occurrences of words near each other. Lucene uses an SSTable-like structure for its term dictionary, and the in-memory index is a finite state automaton, similar to a trie.
Transaction processing or analytics?
A transaction is a group of related reads and writes that form a logical unit. This pattern is known as online transaction processing (OLTP). Data analytics often has different access patterns, such as scanning over a large number of records and only reading a few columns per record to calculate aggregate statistics. These types of queries are often used by business analysts and fed into reports, and this pattern is known as online analytics processing (OLAP).
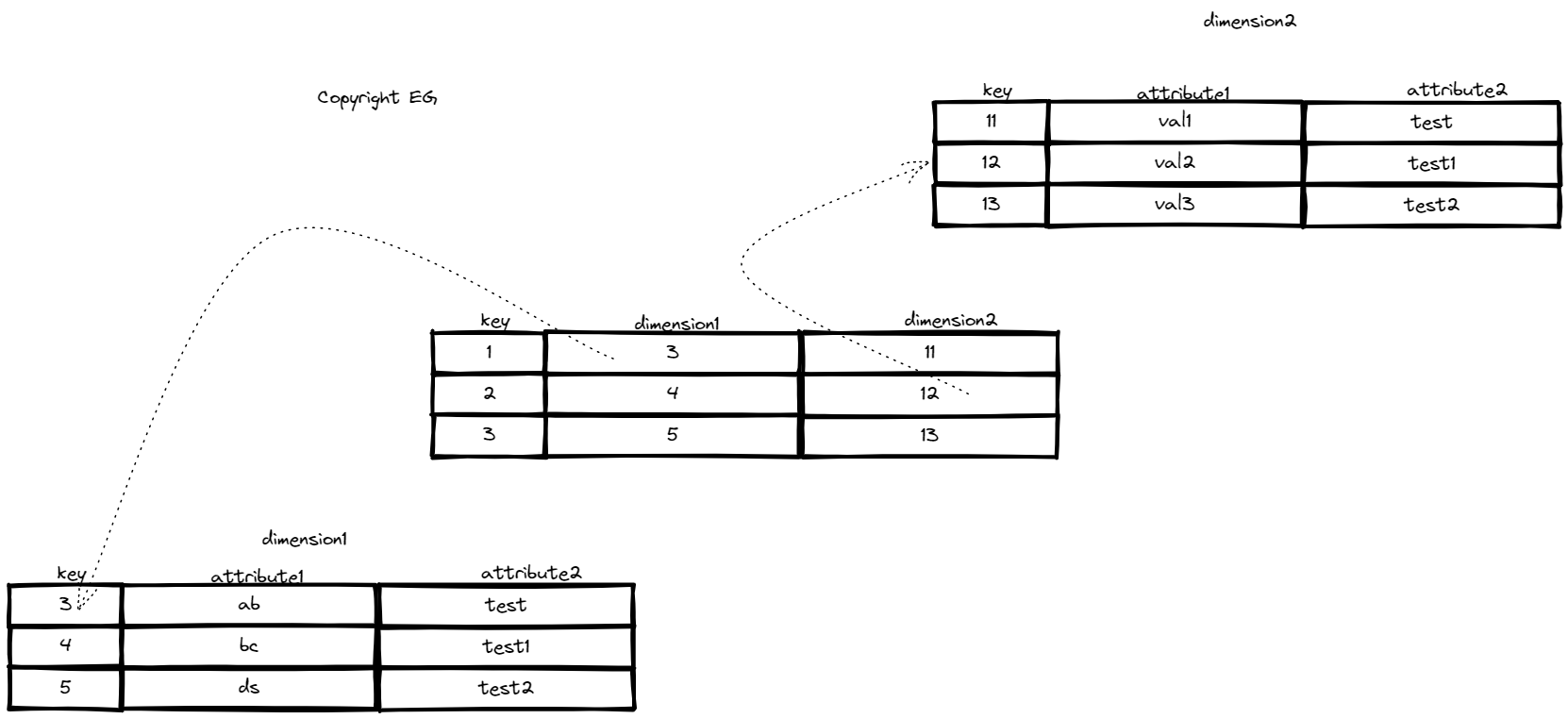
In a data warehouse, data is organized into a star schema where the fact table is in the center, surrounded by its dimension tables, like the rays of a star. This schema is used because it allows for maximum flexibility in analysis. The fact table contains individual events and can be very large, while dimension tables contain details about the events, such as the who, what, where, when, how, and why. These tables can also be very wide, sometimes with over 100 columns. Data warehouses are used for online analytics processing (OLAP) and are separate from online transaction processing (OLTP) databases. They are often created using Extract-Transform-Load (ETL) processes.
Column-oriented storage
Data warehouses often use column-oriented storage engines to optimize the performance of large read-only queries. In this approach, instead of storing all the data for a single row together, each column is stored in a separate file. This allows queries to only read and parse the columns that are needed, reducing the amount of work required. Column-oriented storage also tends to be well-suited for compression, as the sequences of values for each column are often repetitive. This, along with sorting, can help to make read queries faster in data warehouses. However, writes can be more difficult with column-oriented storage, as an update-in-place approach is not possible with compressed columns. One solution to this is the use of materialized views, which are pre-computed, denormalized copies of query results. These can be updated automatically when the underlying data changes, but this can make writes more expensive.
Summary
In summary, we discussed the differences between storage engines for online transaction processing (OLTP) and online analytics processing (OLAP). It also covered the various indexing structures used by storage engines, including B-trees, LSM-trees, and column-oriented storage. The post also briefly discussed in-memory databases and data warehouses. Overall, the chapter aimed to provide a high-level understanding of how databases handle storage and retrieval, and how different storage engines are optimized for different workloads.
Did you find it useful? Let me know it the comments. Keep on crushing it!